🌈大数据平台全生态搭建

For Graduation Papers
安装虚拟机
VMWARE安装ubuntu-server16.04,步骤略过
修改Ubuntu的root用户名
输入sudo passwd root,键入你的本地用户密码,随后更新你的root用户密码
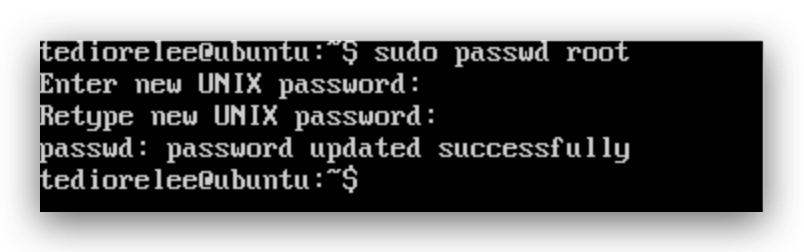
使用su root即可切换到root用户下
配置静态IP
使用root身份编辑/etc/network/interface下的eth0网卡

以我本地网关为192.168.6.1为例,将虚拟机IP定为192.168.6.22,DNS填上本地电信的DNS
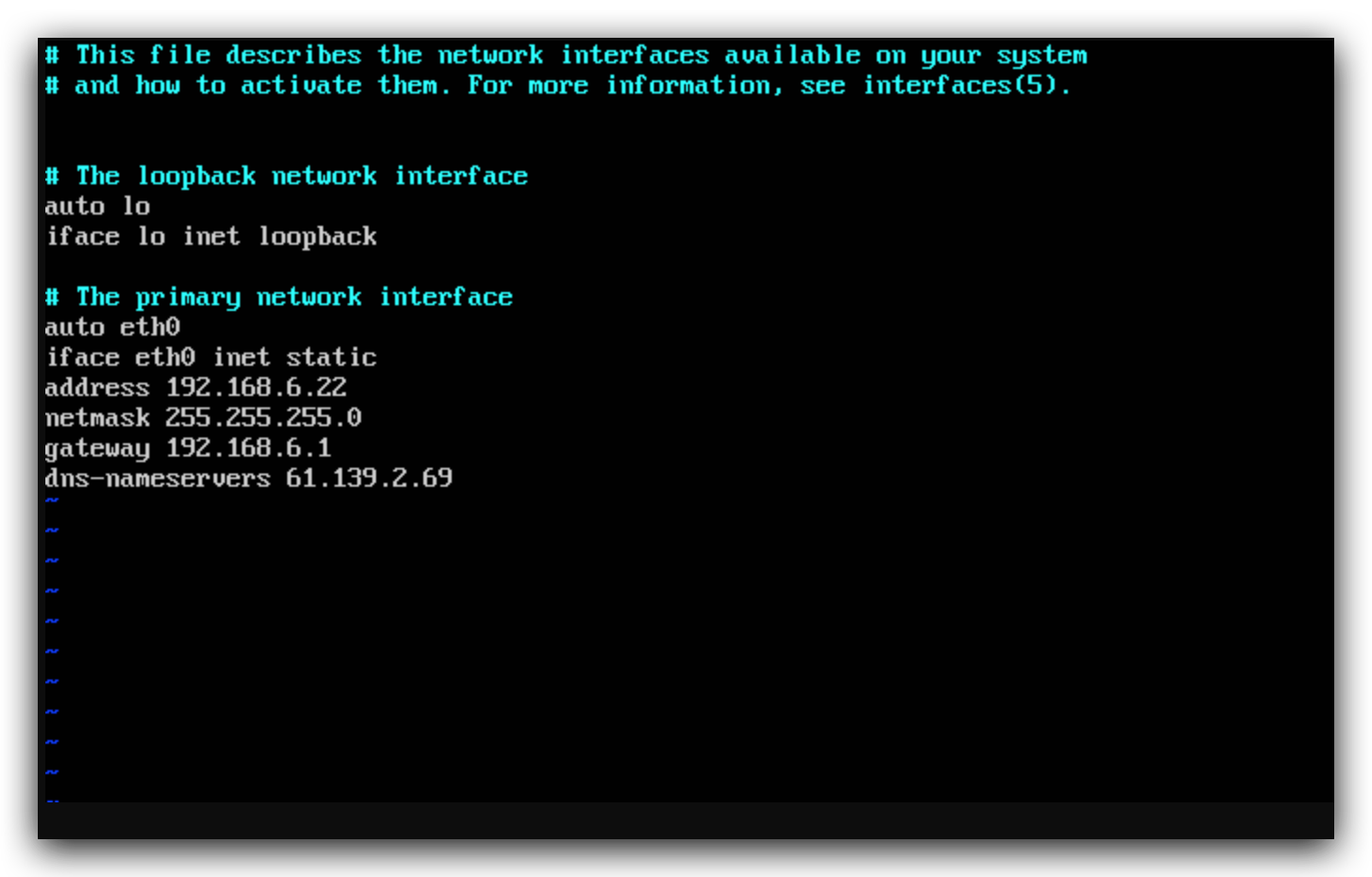
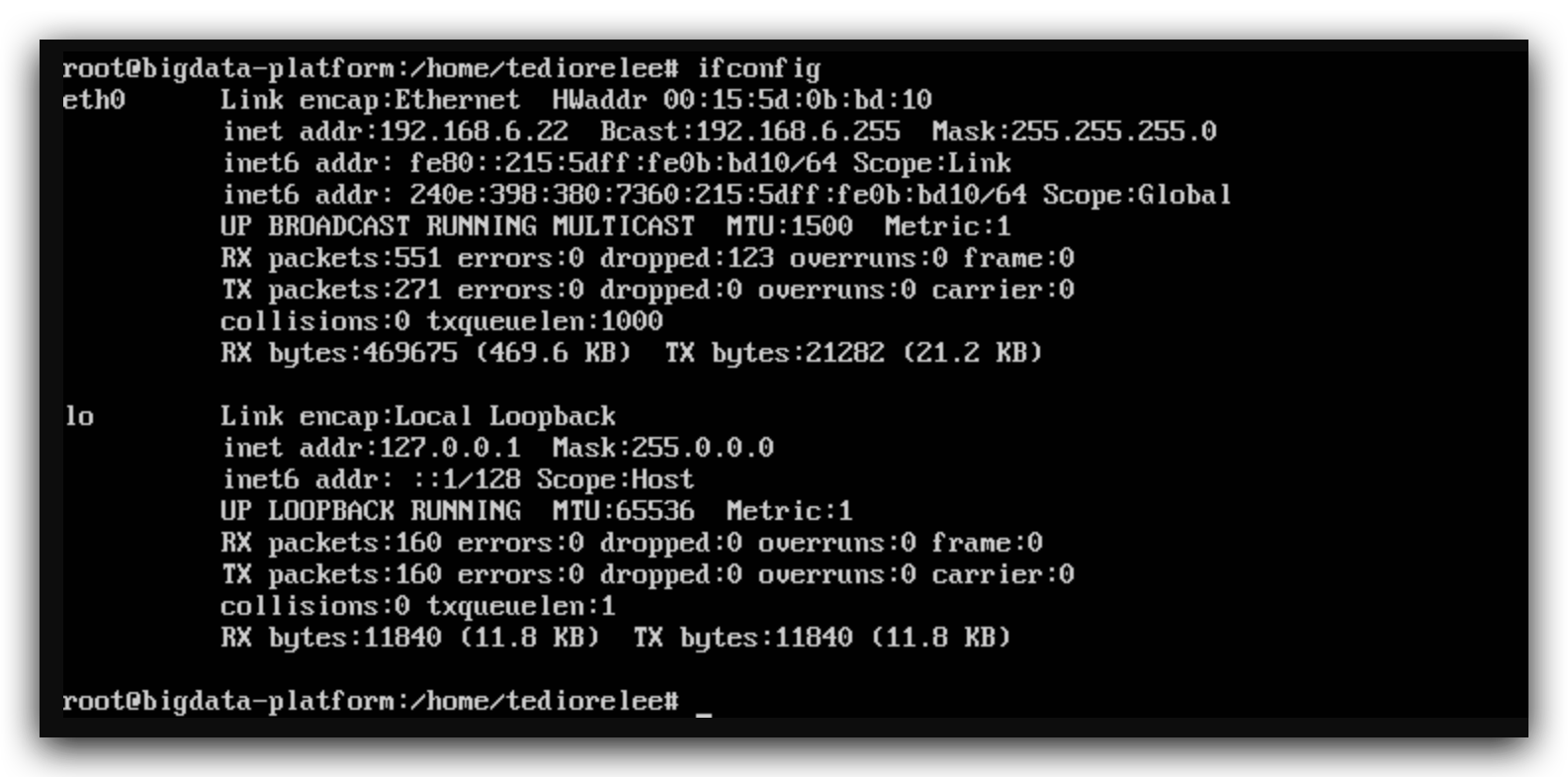
保存退出,使用命令ifdown eth0卸载网卡,再使用命令ifup eth0重新启用网卡即可使修改生效。

这时候再用ifconfig查看网卡配置即可看到修改成功。
配置SSH登录
root用户下,使用命令apt-get install ssh
等待安装完成即可
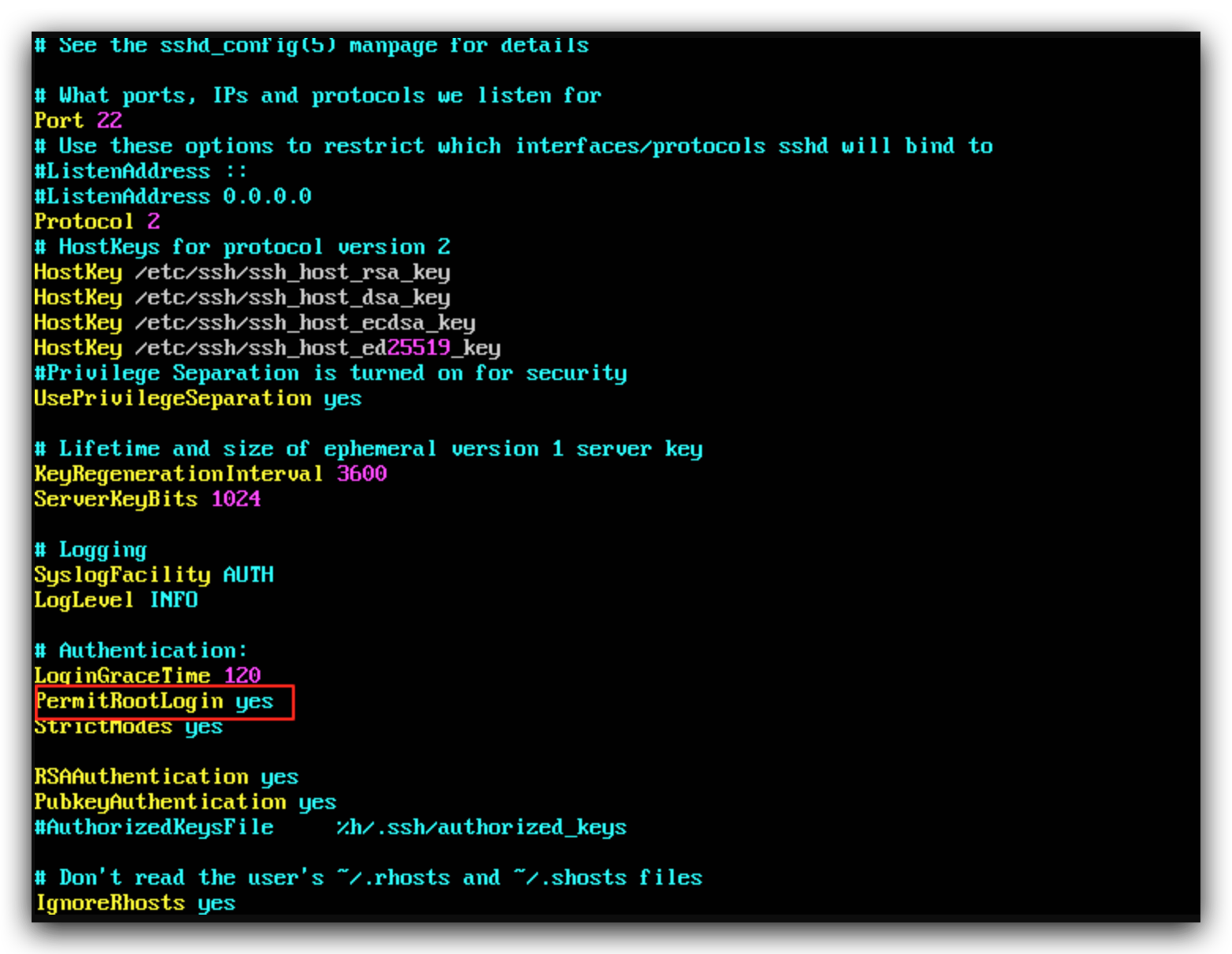
vim编辑etc/ssh/sshd_config
找到PermitRootLogin字段,修改为yes
保存退出
service ssh restart重启ssh服务

使用ssh工具即可连接
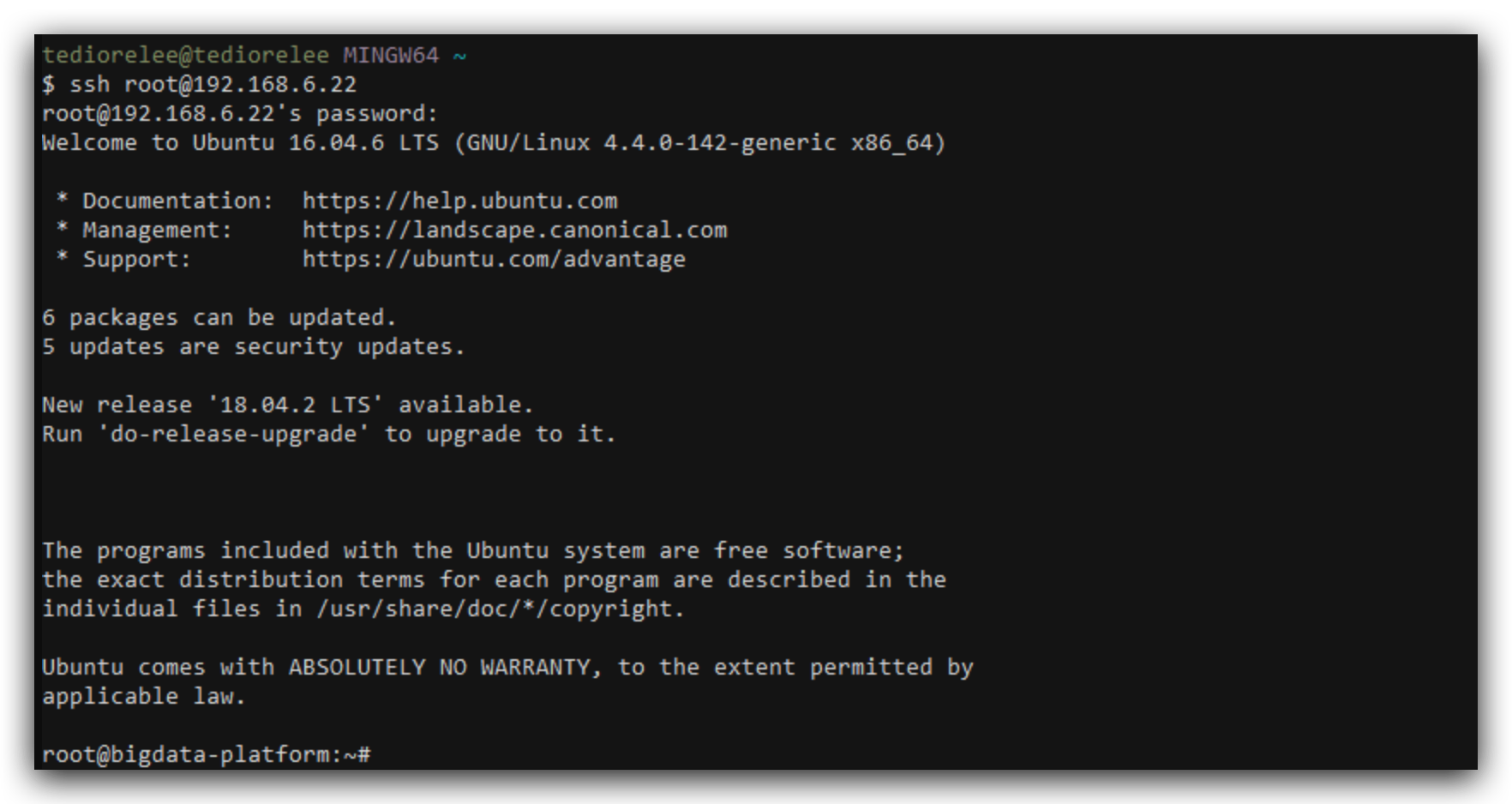
修改软件源
找到阿里巴巴开源镜像站里面的Ubuntu,点击后面的帮助

选择你对应的Ubuntu版本,复制软件源信息,粘贴到/etc/apt/sources.list里
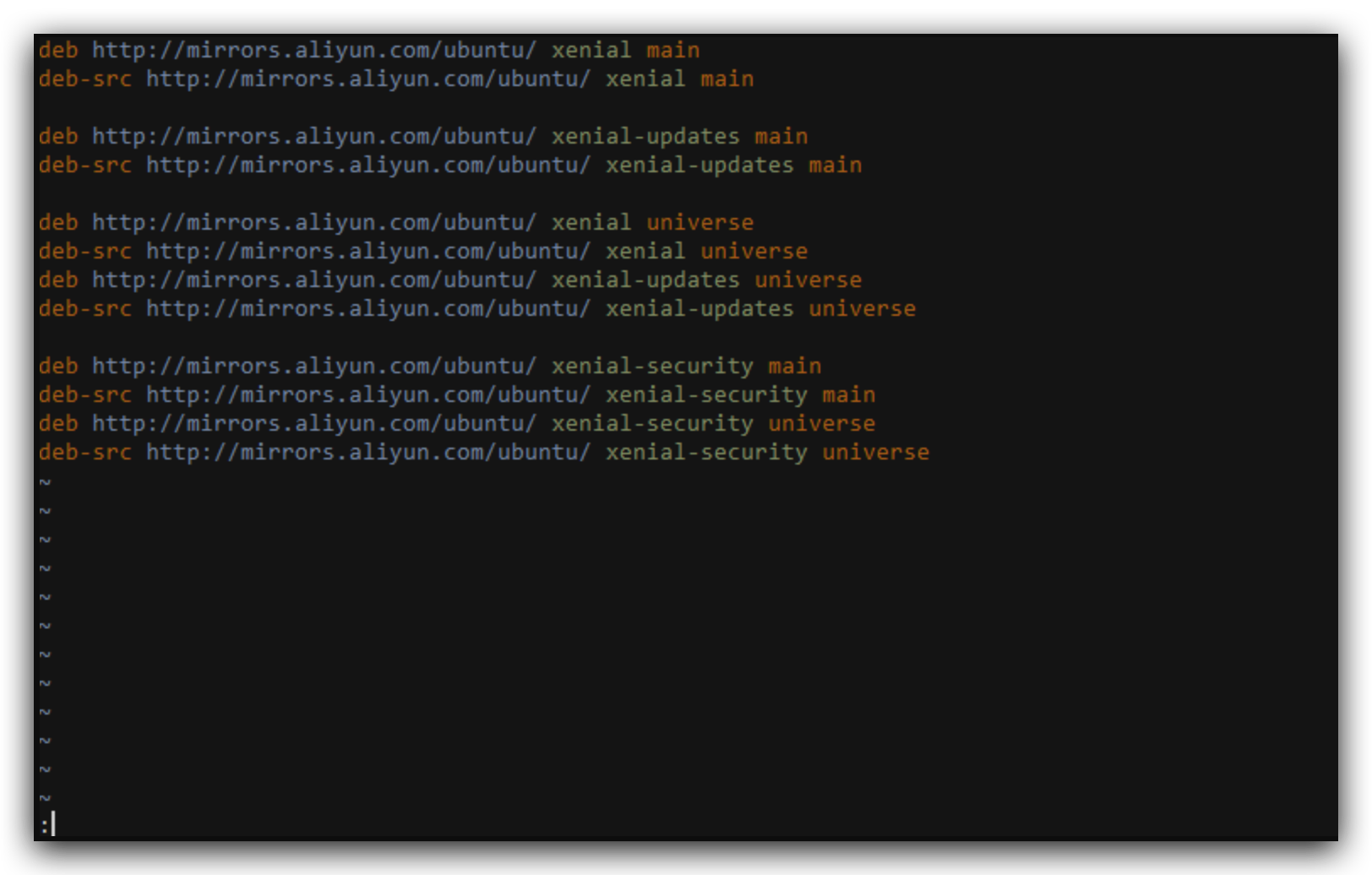
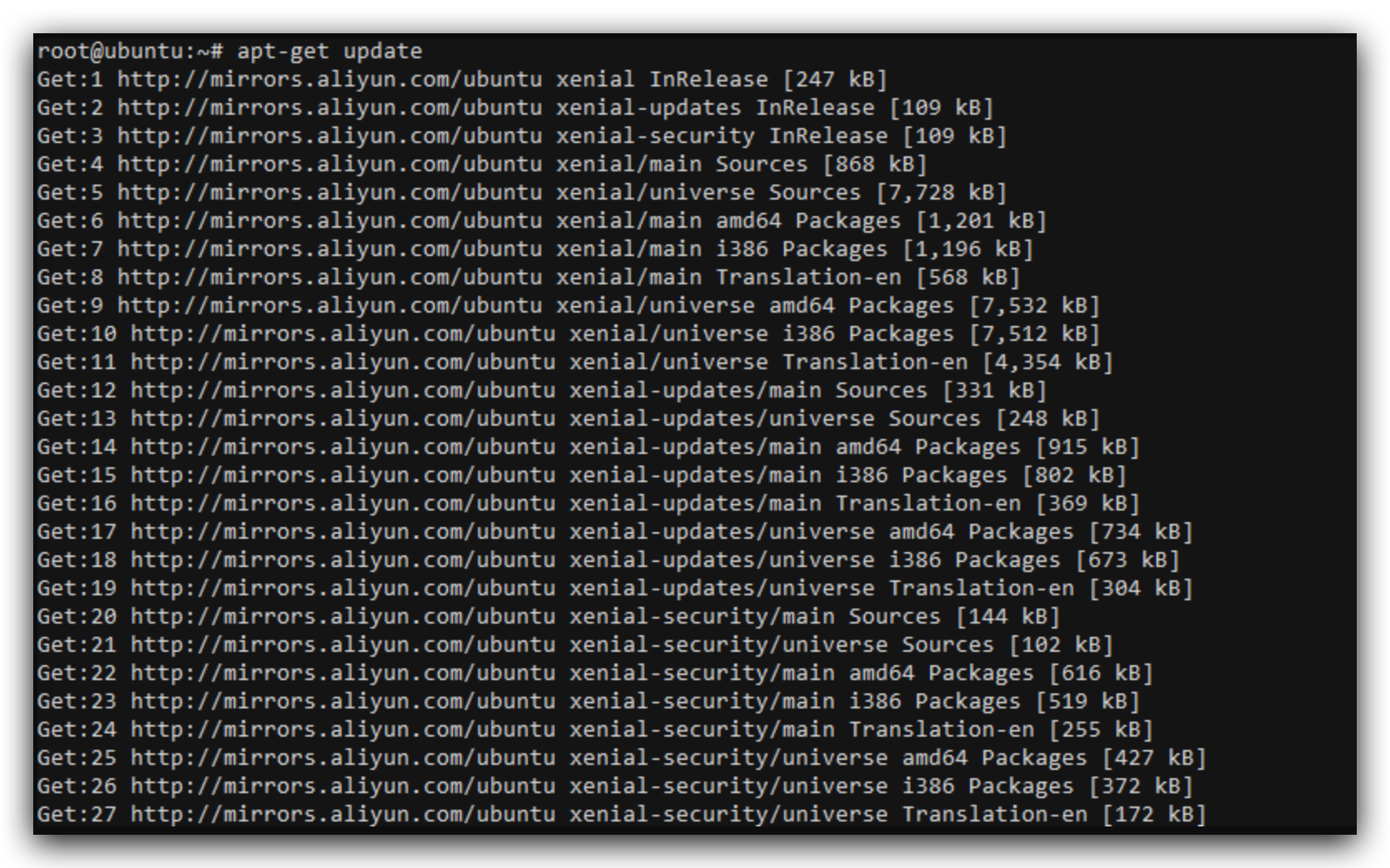
保存退出即可,之后我们可以apt-get update一下,重新更新一下软件源
安装JDK
新建mkdir /usr/local/jdk文件夹
使用Winscp工具上传jdk包到/usr/local文件夹里
tar -zxvf jdkxxx.tar.gz解压缩
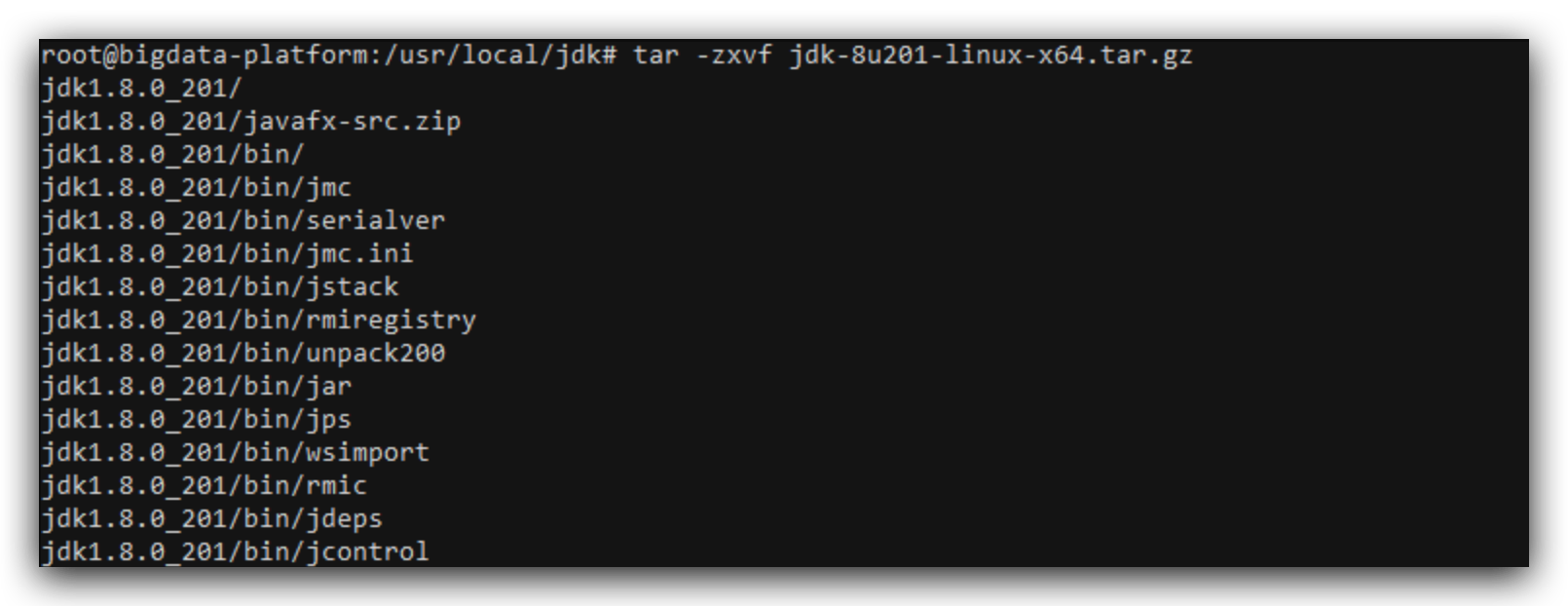
添加jdk的环境变量
打开文件vim /etc/profile在末尾加上

export JAVA_HOME=/usr/local/jdk/jdk1.8.0_201
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.ja$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
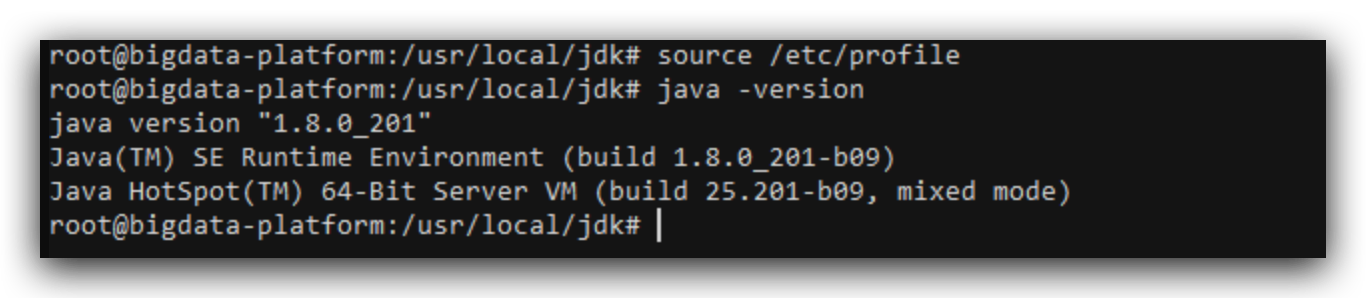
保存并退出,source /etc/profile使其生效
这时输入java -version即可查看到版本信息表示jdk安装成功
配置SSH免密登录
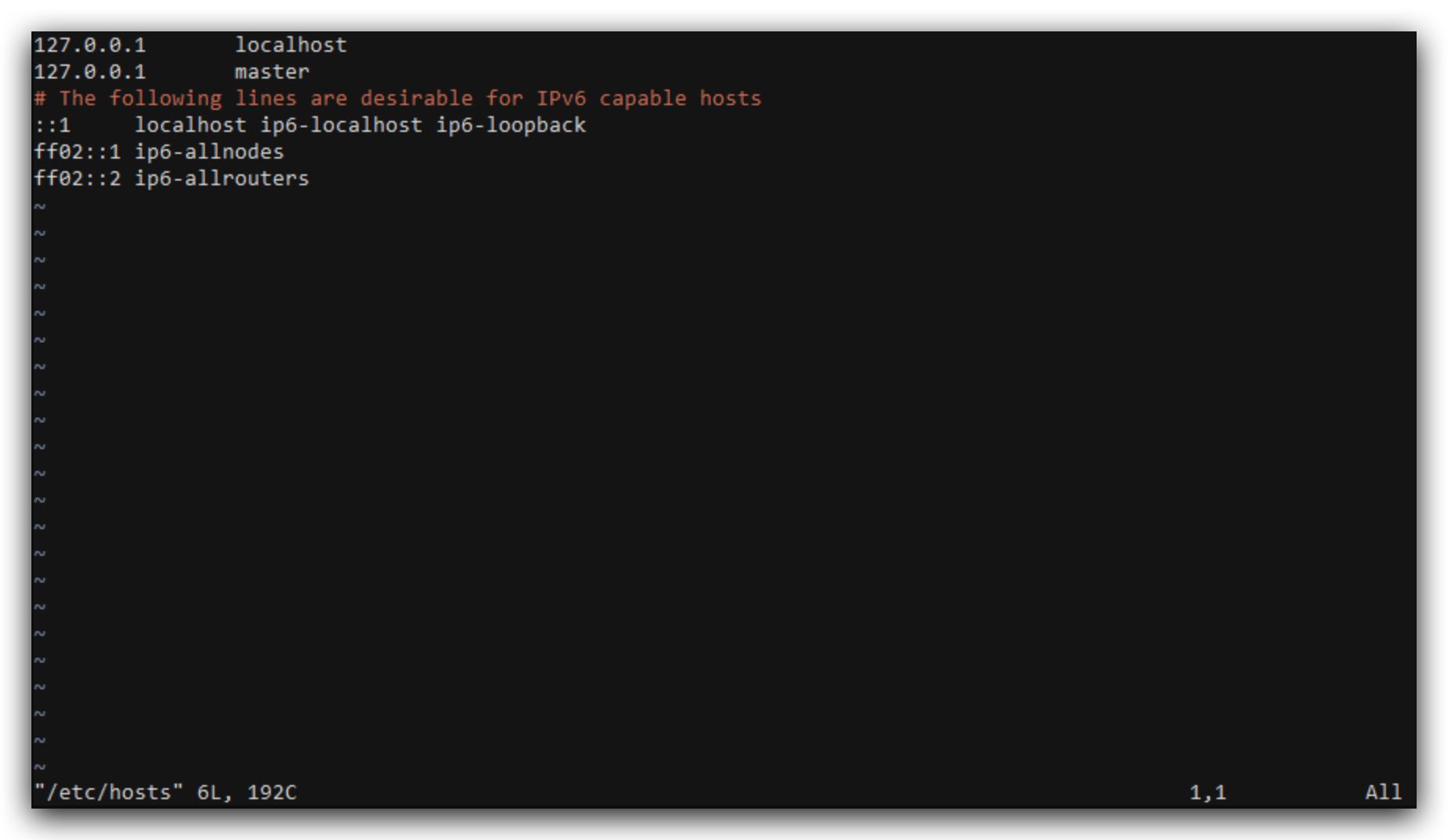
这里的主机名我定义为master
修改/etc/hosts,把master的ip地址修改为127.0.0.1,保存退出
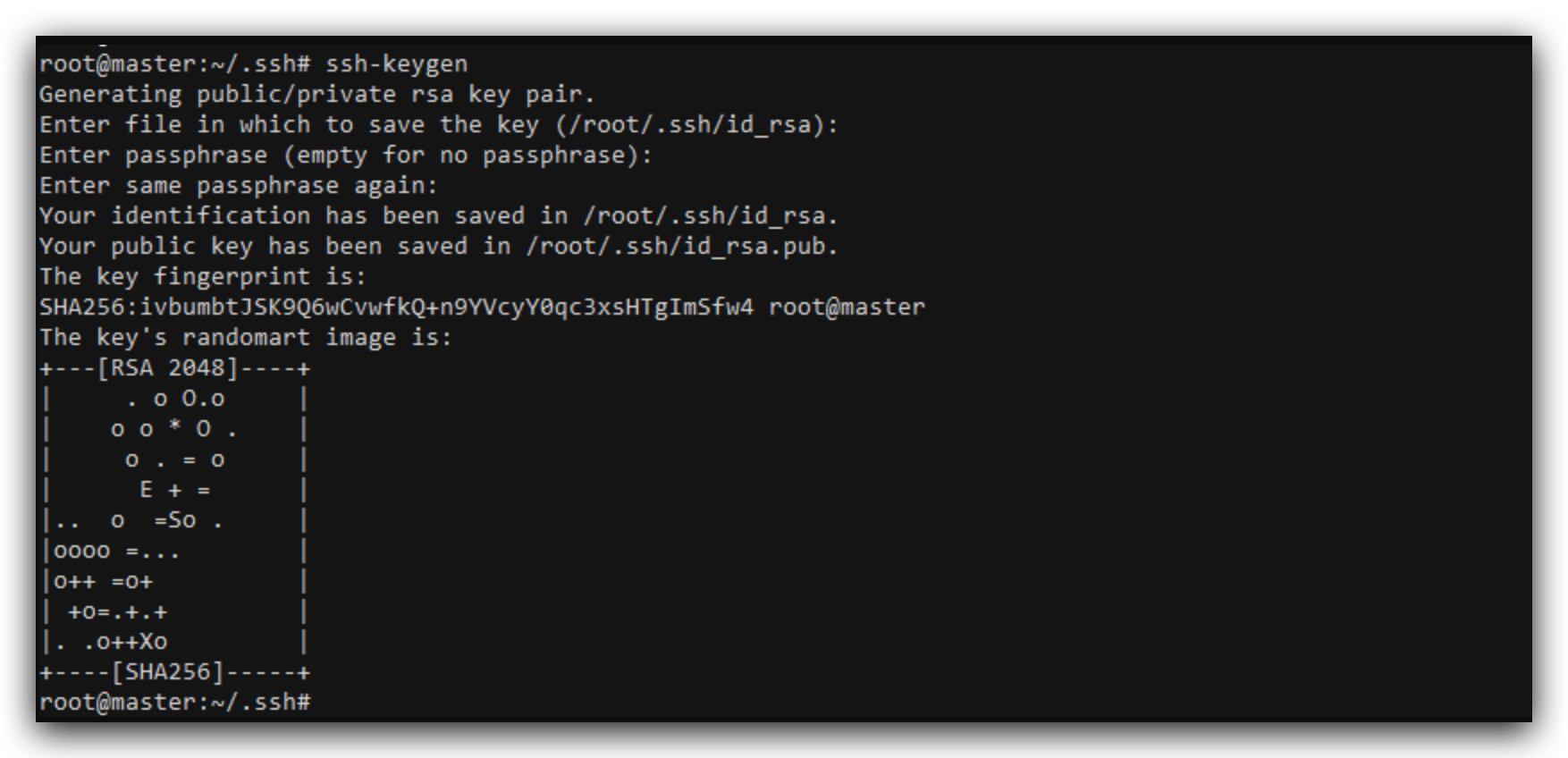
进入.ssh文件夹,删除原有多余的公钥和私钥
ssh-keygen生成新的ssh密钥,一路回车确定
将公钥复制到authorized_keys里面
cat id_rsa.pub >> ~/.ssh/authorized_keys
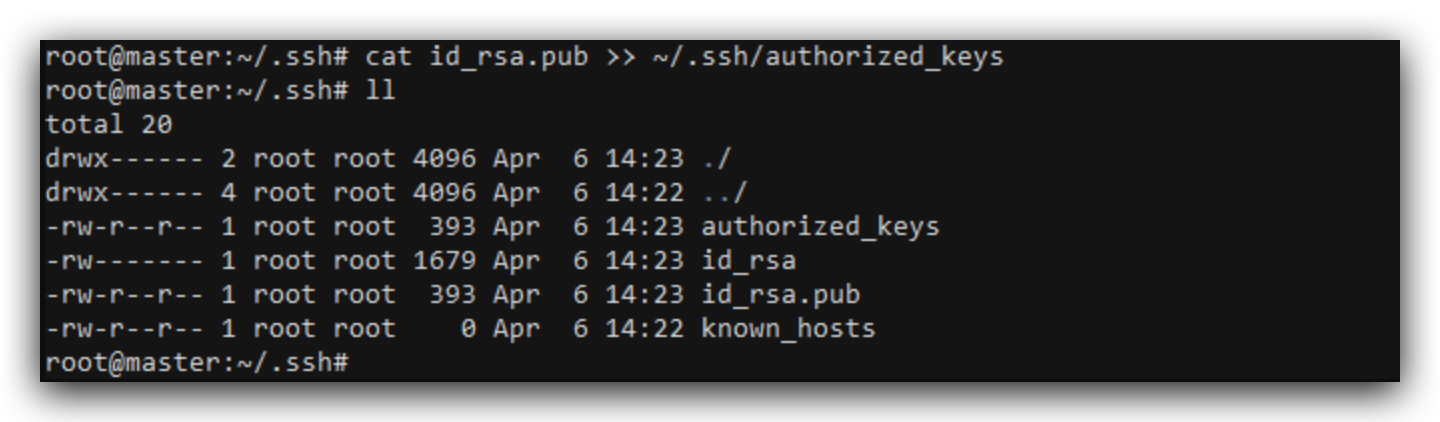
测试登录,ssh master
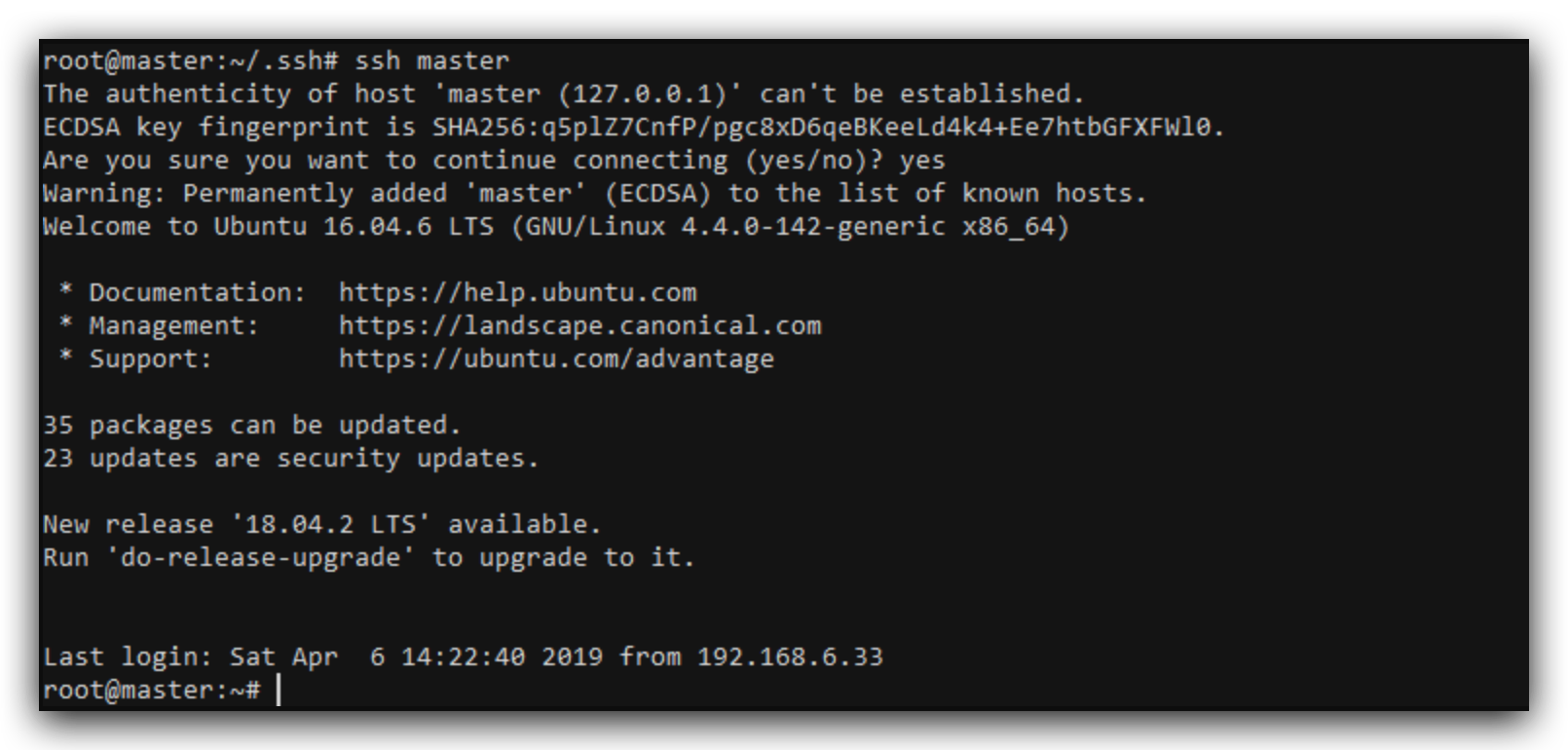
成功实现ssh免密登录
安装Hadoop
介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
HDFS,Hadoop Distributed File System,是一个分布式文件系统,用来存储 Hadoop 集群中所有存储节点上的文件,包含一个 NameNode 和大量 DataNode。NameNode,它在 HDFS 内部提供元数据服务,负责管理文件系统名称空间和控制外部客户机的访问,决定是否将文件映射到 DataNode 上。DataNode,它为 HDFS 提供存储块,响应来自 HDFS 客户机的读写请求。
MapReduce是一种编程模型,用于大规模数据集的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,即指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
在/usr/local中新建hadoop文件夹,使用winscp上传hadoop安装包
解压缩hadooptar -zxvf hadoop-2.6.4.tar.gz
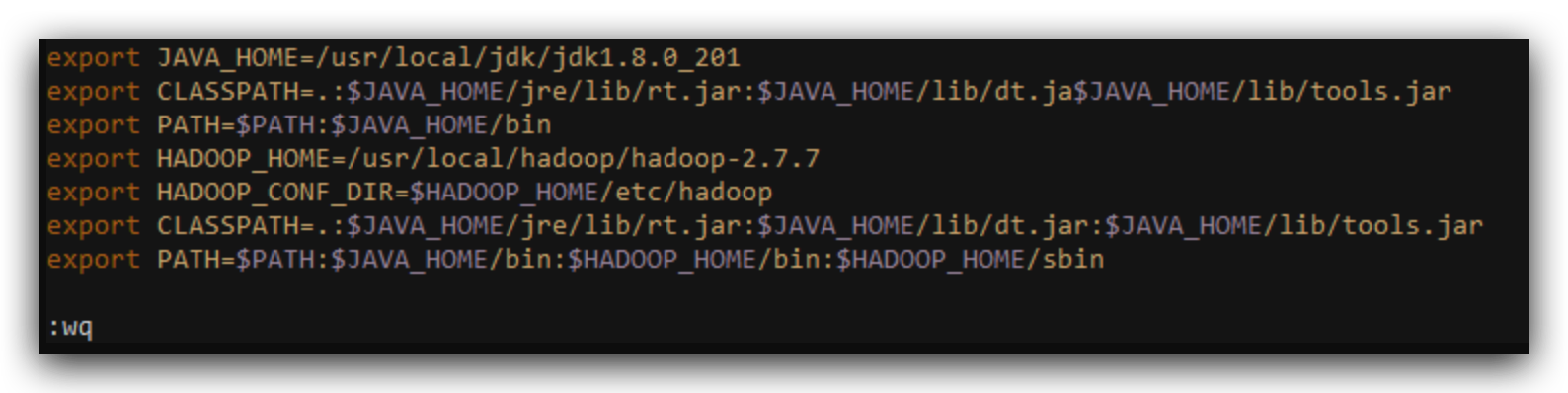
配置环境变量
vim /etc/profile,后面加上
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export
CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile使其生效
编辑hadoop-env.sh、mapred-env.sh、yarn-env.sh文件,修改JAVA_HOME参数为
export JAVA_HOME="/usr/local/jdk"

配置core-site.xml
vim {HADOOP_HOME}/etc/hadoop/core-site.xml
修改为:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/data</value>
</property>
</configuration>
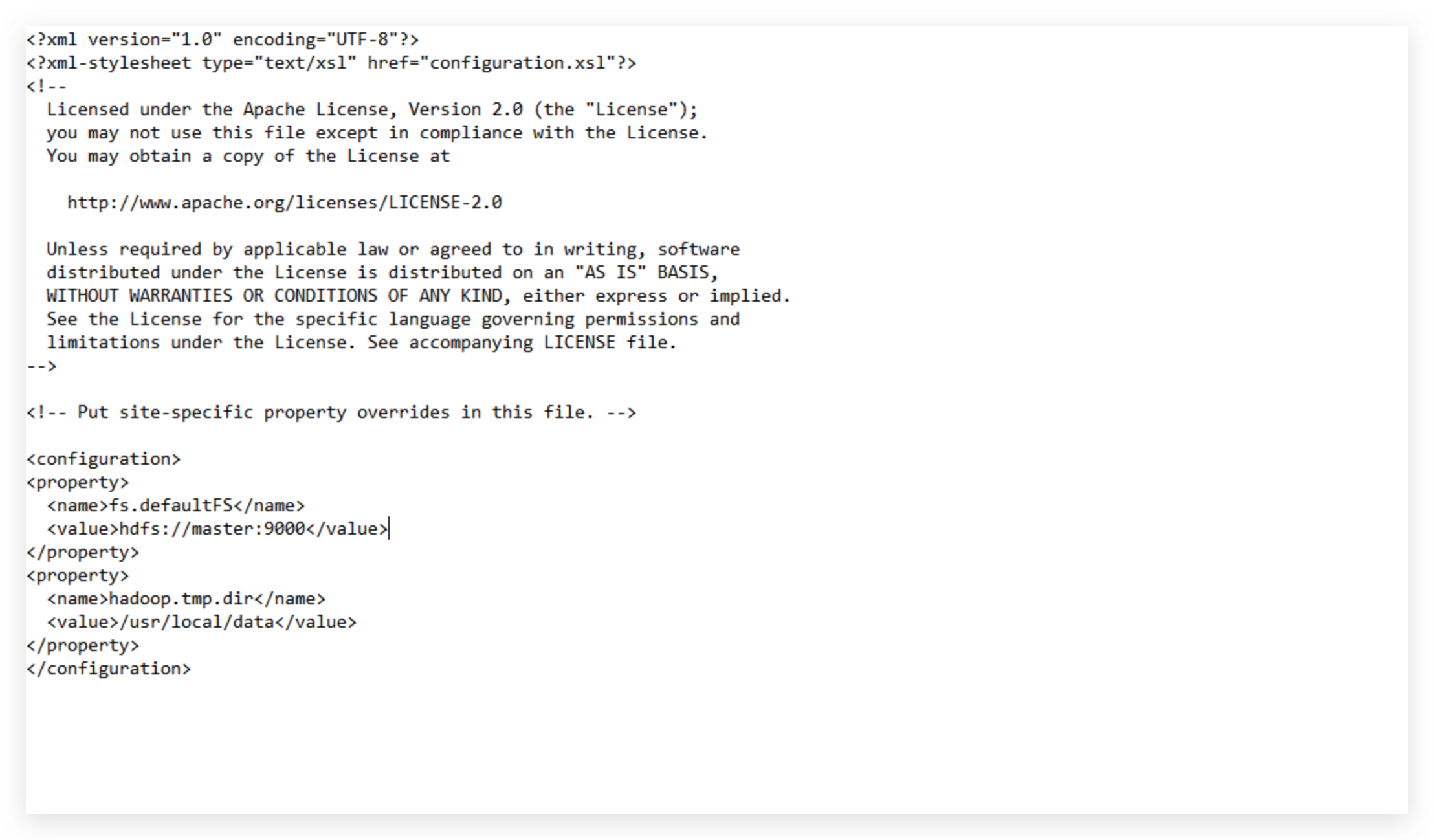
注意:这里的hadoop.tmp.dir修改为自己创建的临时文件存放目录
配置hdfs-site.xml
vim ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
修改为:
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/data/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
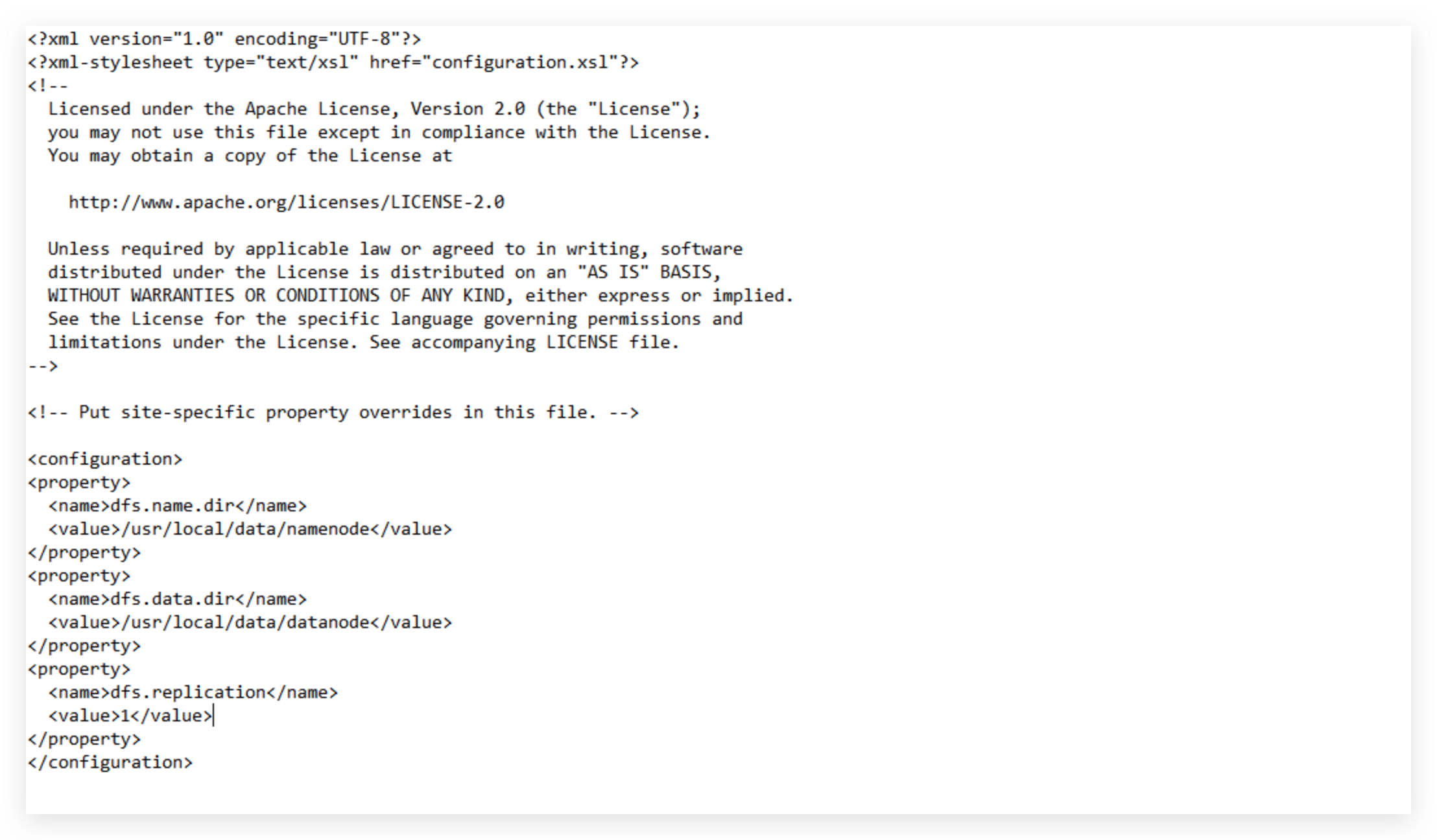
注意:因为这里是伪分布式环境只有一个节点,所以这里设置为1
配置mapred-site.xml
修改文件名
cp mapred-site.xml.template mapred-site.xml
vim ${HADOOP_HOME}/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
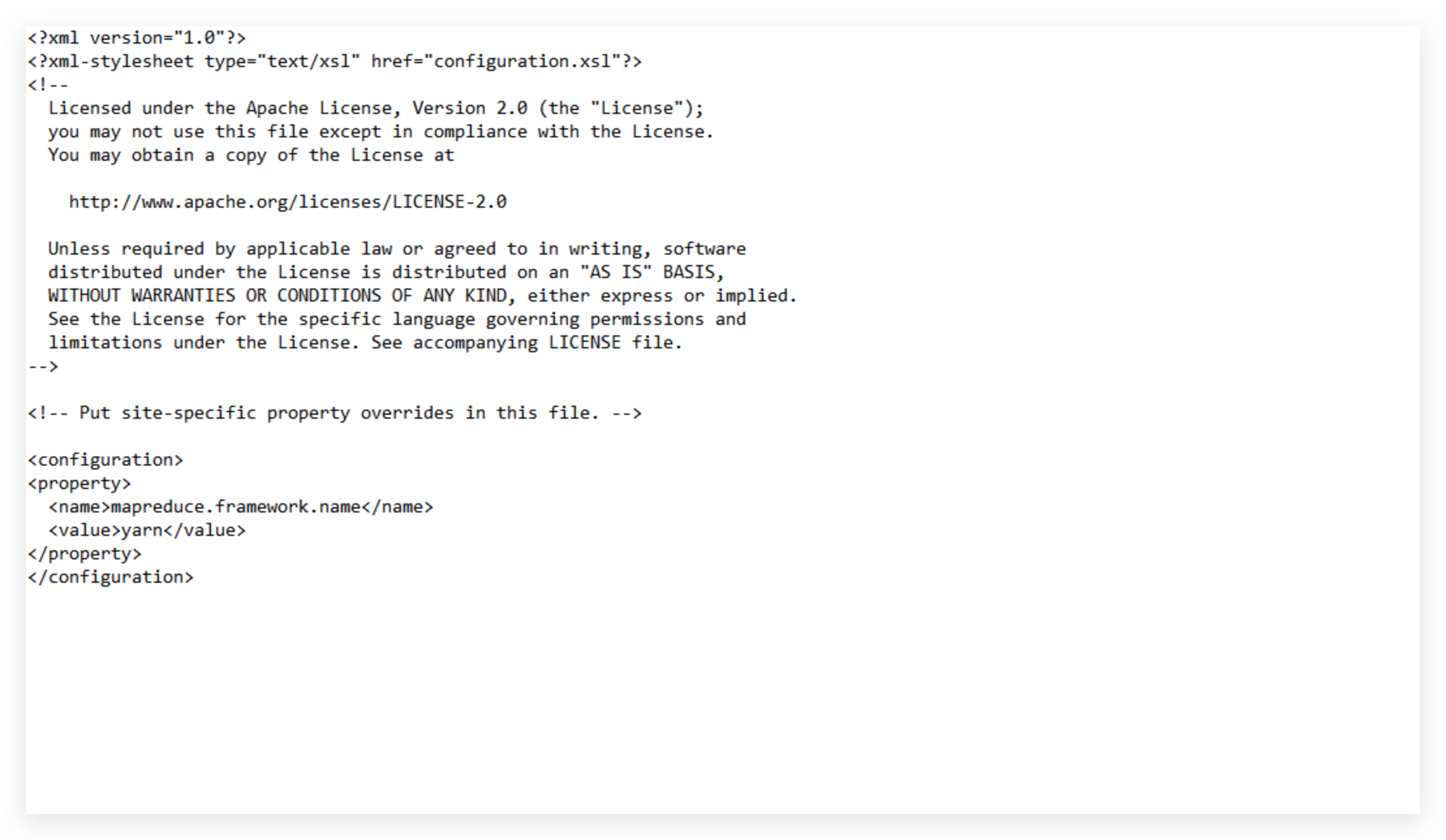
配置yarn-site.xml
vim ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
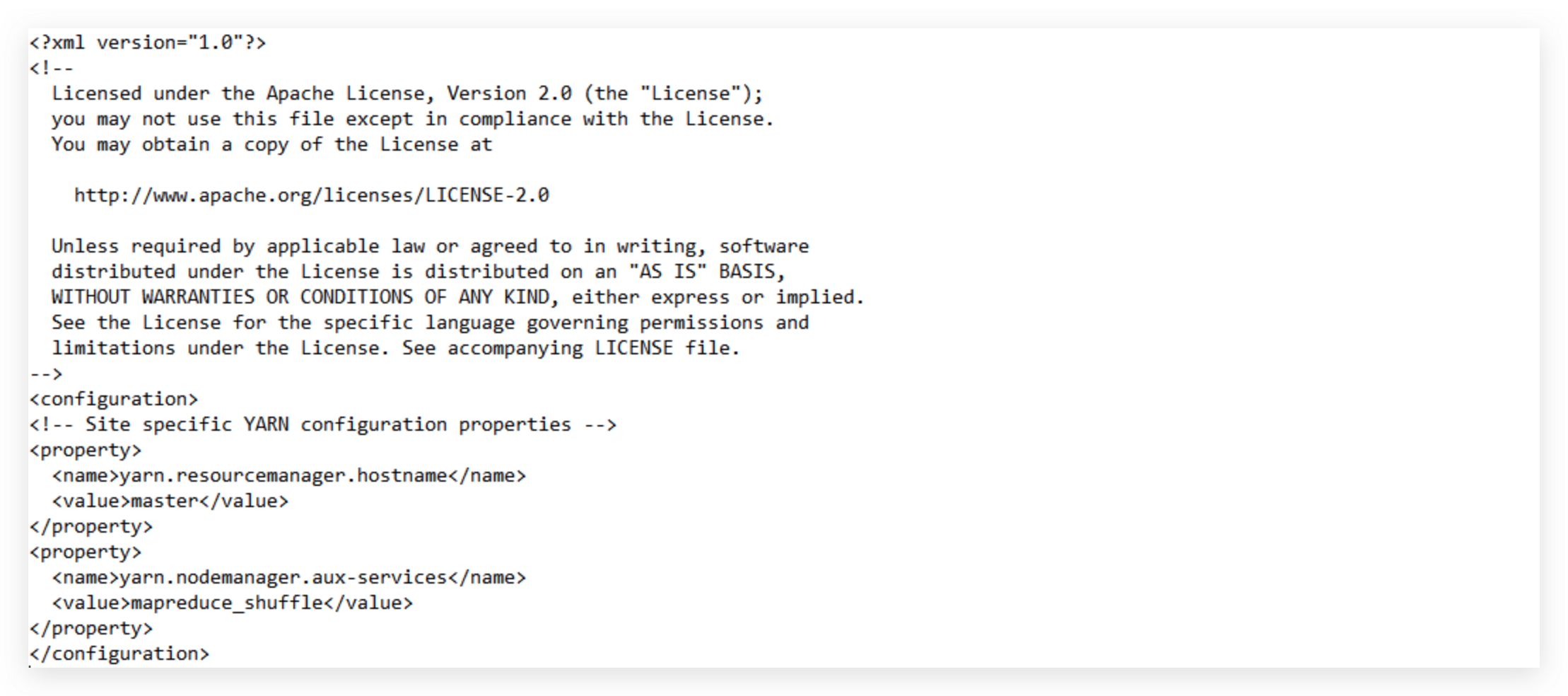
测试
- 格式化hdfs
hdfs namenode –format
- 启动hdfs
root@bigdata-platform:/usr/local# cd /usr/local/hadoop/hadoop-2.7.7/
root@bigdata-platform:/usr/local/hadoop/hadoop-2.7.7# sbin/start-dfs.sh

- 启动yarn
root@bigdata-platform:/usr/local/hadoop/hadoop-2.7.7# sbin/start-yarn.sh

- jps查看
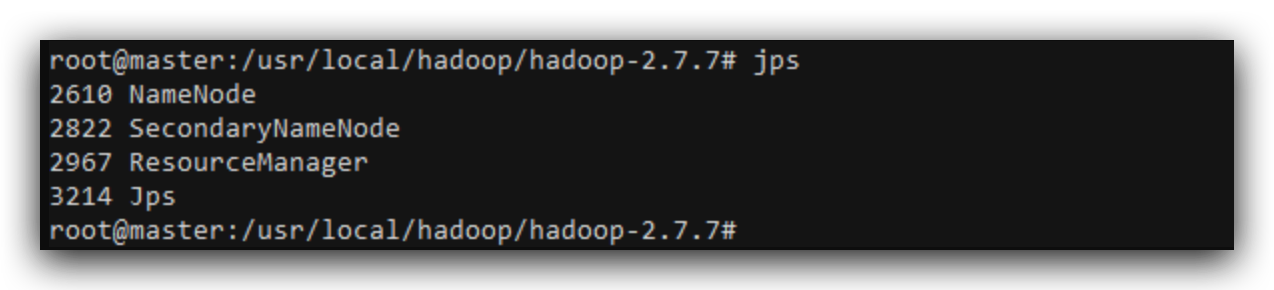
可以看到所有节点都启动成功,打开http://192.168.6.22:50070可以查看可视化页面。
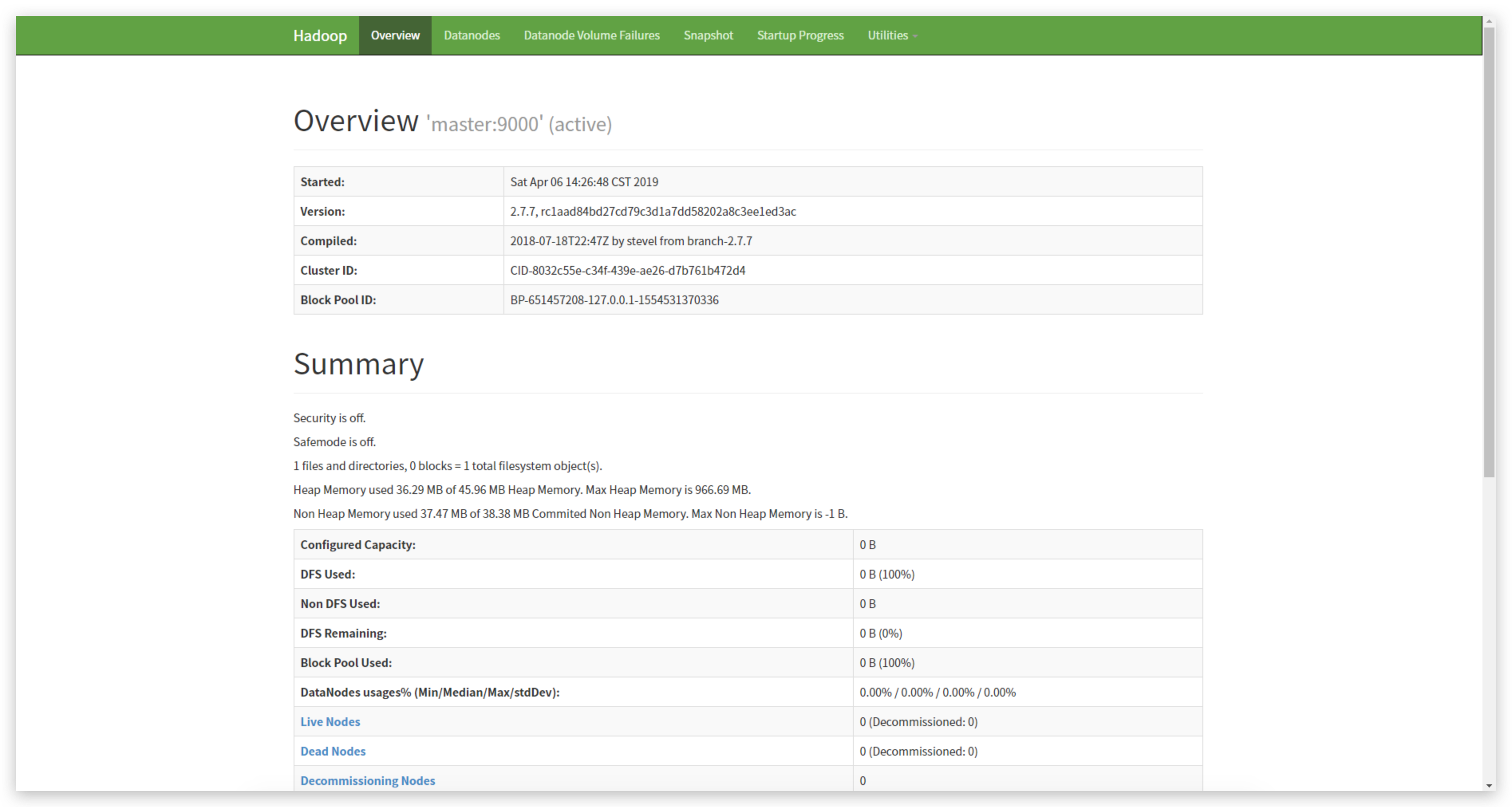
到此为止,HADOOP的安装就完成了。
安装Hive
介绍
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过和SQL类似的HiveQL语言快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive 没有专门的数据格式。所有Hive 的数据都存储在Hadoop兼容的文件系统(例如HDFS)中。Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。
环境配置
注意:Hive只需要在master节点上安装配置
在usr/local下新建hive文件夹,使用winscp上传hive安装包
cd /usr/local/hive进入hive文件夹,使用tar -zxvf apache-hive-2.3.4-bin.tar.gz解压
添加Hive环境变量
在etc/profile中,添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
和原有的变量整合一下,如图
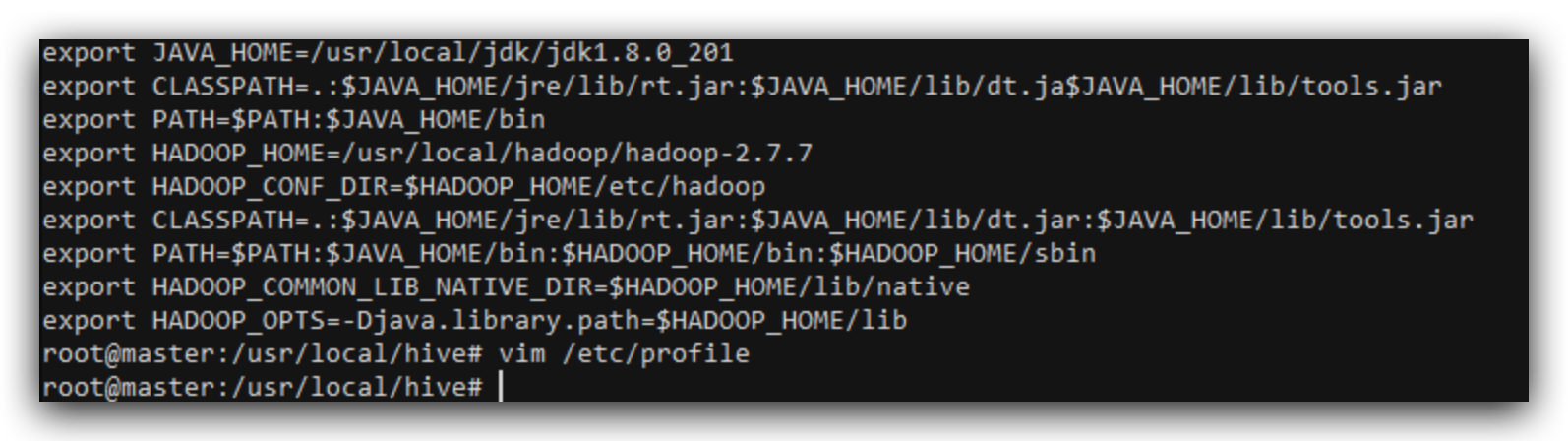
source /etc/profile保存一下即可
配置hive-site.xml
进入hive文件夹,复制一份hive-site.xml
cp hive-default.xml.template hive-site.xml
由于hive-site.xml文件过长,最好复制到虚拟机外修改之后再拷贝回来
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive_metadata?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/usr/local/hive/hive-2.3.4/tmp/hadoop</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/usr/local/hive/hive-2.3.4/tmp/hadoop/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/hive/hive-2.3.4/tmp/hadoop</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/hive/hive-2.3.4/tmp/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
配置hive-env.sh文件
复制一份配置文件
cp hive-env.sh.template hive-env.sh
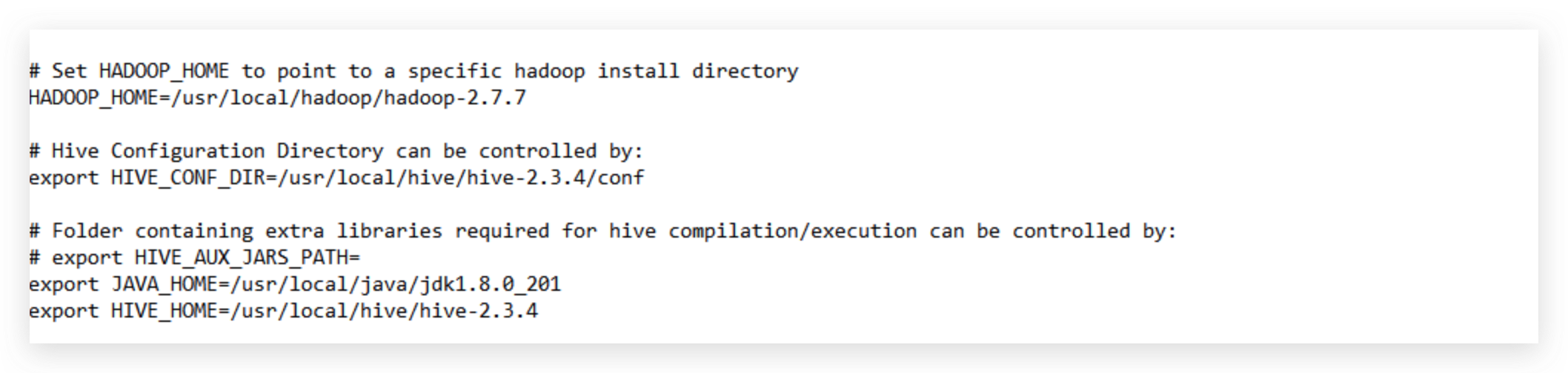
找到如下位置,做对应修改
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/usr/local/hive/hive-2.3.4/conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
# export HIVE_AUX_JARS_PATH=
export JAVA_HOME=/usr/local/java/jdk1.8.0_201
export HIVE_HOME=/usr/local/hive/hive-2.3.4
如图所示:
下载mysql-connector-java.jar
将该jar包放进/usr/local/hive/hive-2.3.4/lib/中即可
安装并配置mysql
安装mysql-server
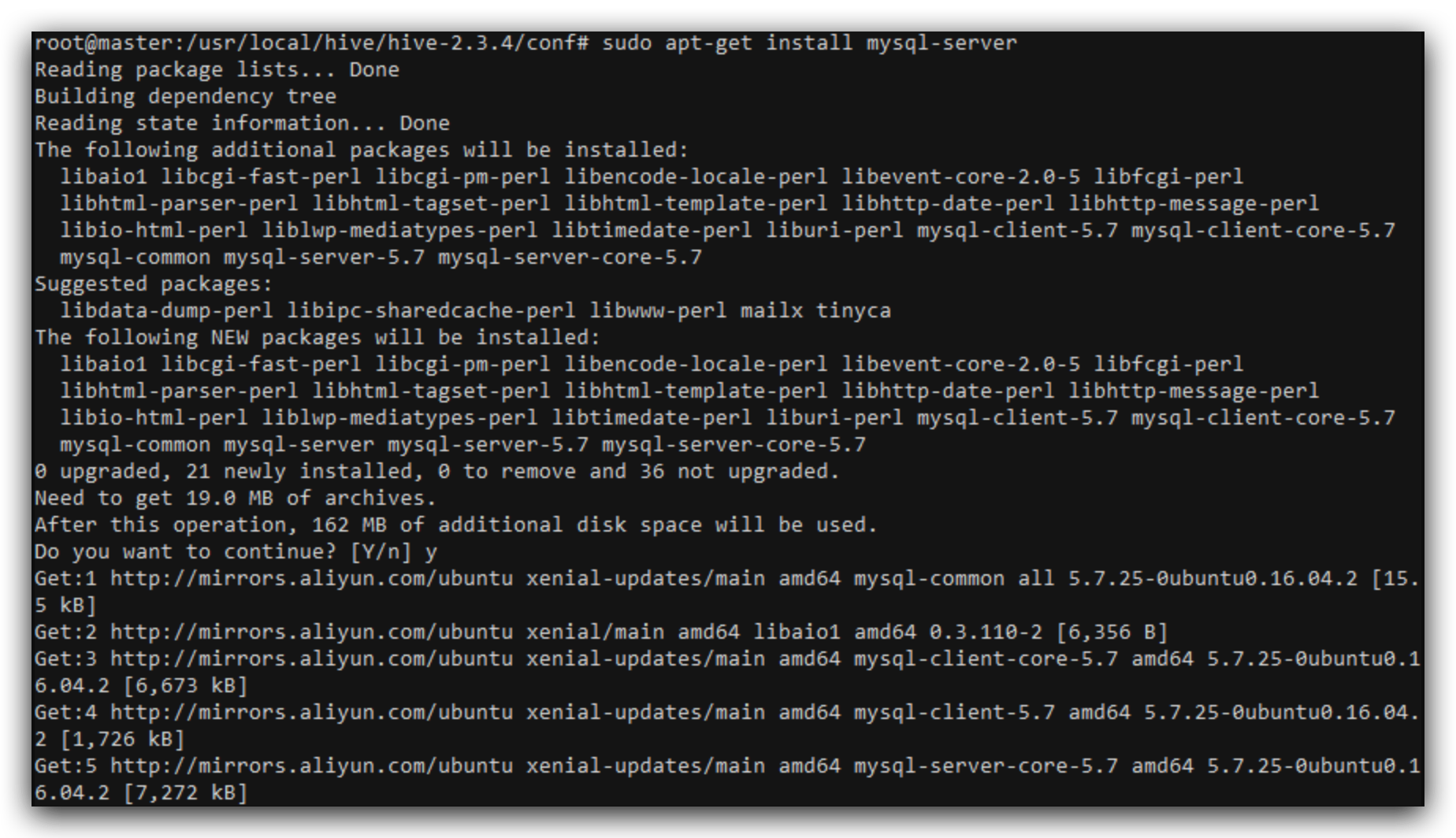
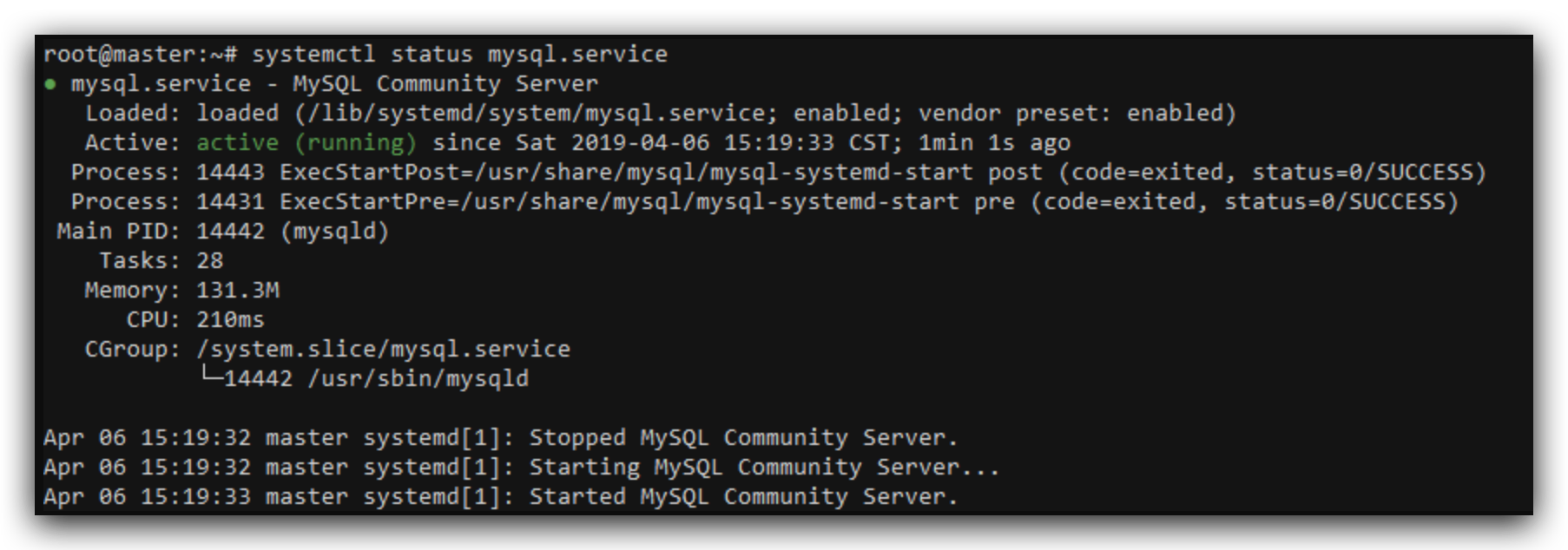
完成之后,systemctl status mysql.service可以查看当前状态
Mysql上创建hive元数据库,创建hive账号,并进行授权
安装Zookeeper
介绍
ZooKeeper是一个分布式的应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。其目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper是一个分布式的应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。其目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
那么Zookeeper能做什么事情呢?举个简单的例子:假设我们有20个搜索引擎的服务器(每个负责总索引中的一部分的搜索任务)和一个总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕机时替换总服务器),一个web的cgi(向总服务器发出搜索请求)。搜索引擎的服务器中的15个服务器提供搜索服务,5个服务器正在生成索引。这20个搜索引擎的服务器经常要让正在提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以提供搜索服务了。使用Zookeeper可以保证总服务器自动感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,当总服务器宕机时自动启用备用的总服务器。
环境配置
使用winscp上传zookeeper安装包
新建文件夹mkdir zookeeper
解压缩tar -zxvf zookeeper-3.4.10.tar.gz
编辑vim /etc/profile,对比添加和修改:
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin
如图所示:
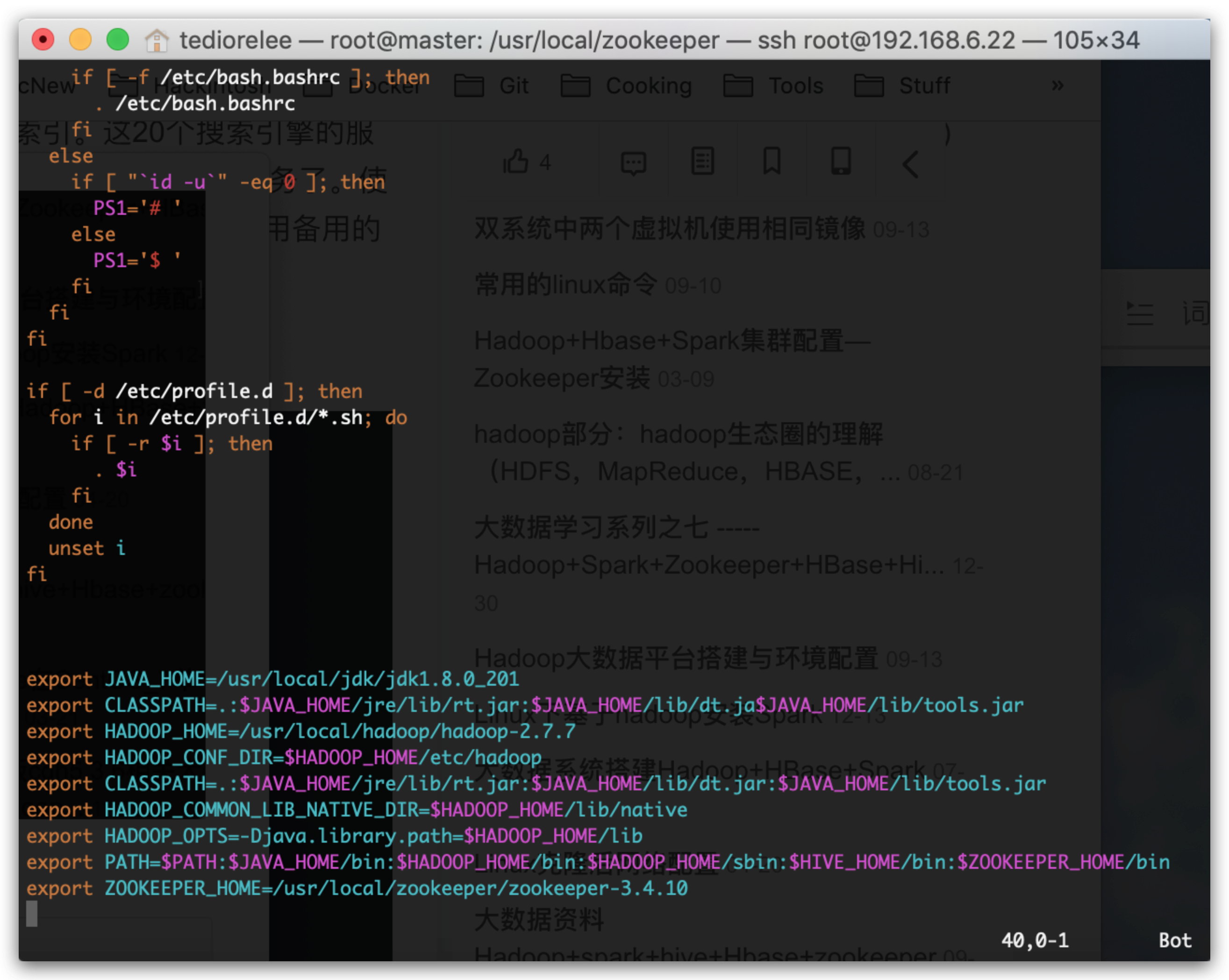
保存退出并source /etc/profile使其生效
配置zoo.cfg文件
cd /usr/local/zookeeper/zookeeper-3.4.10/conf
cp zoo_sample.cfg zoo.cfg
将datadir修改为自己的地址,并在文件末尾加上如图所示字段
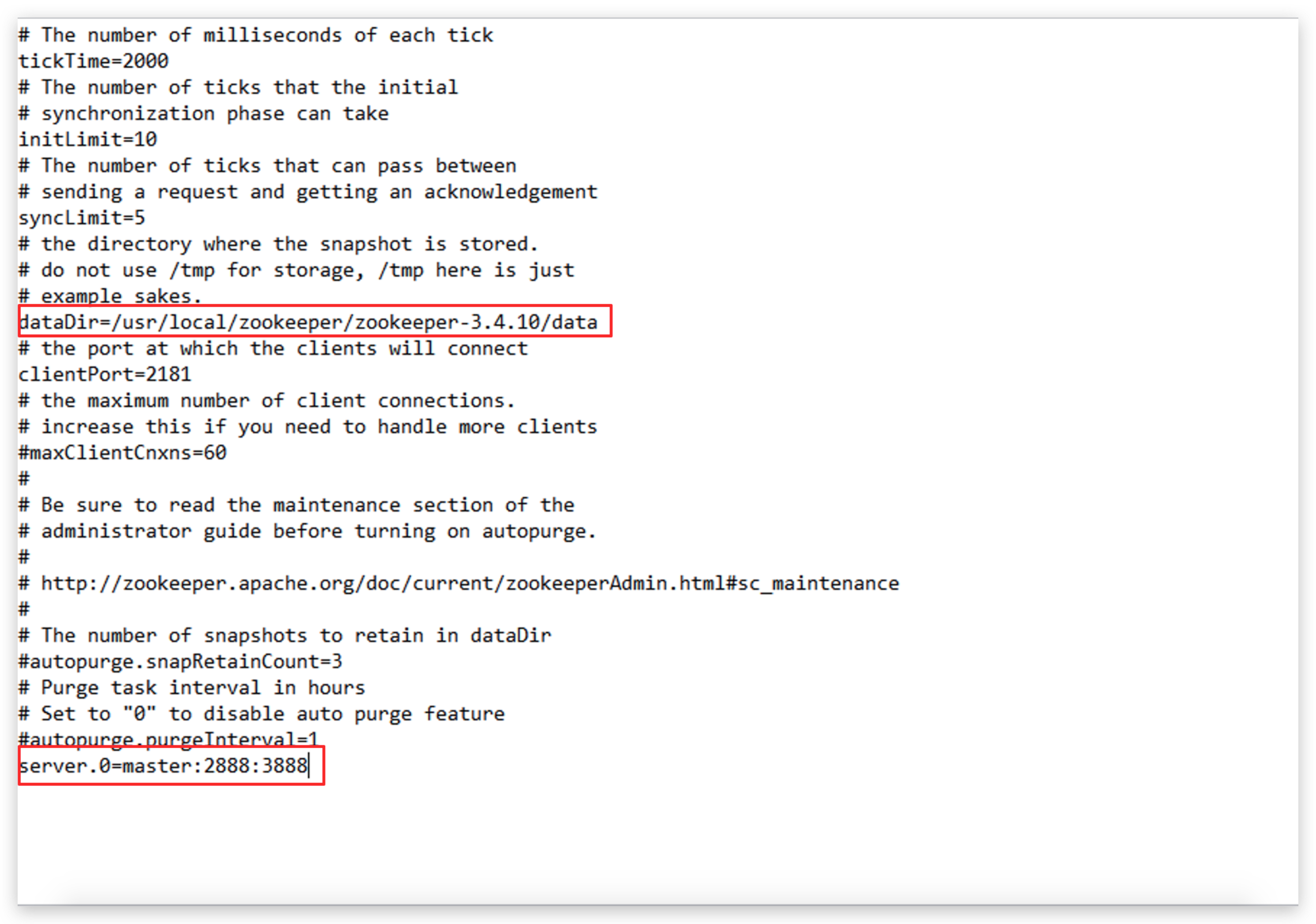
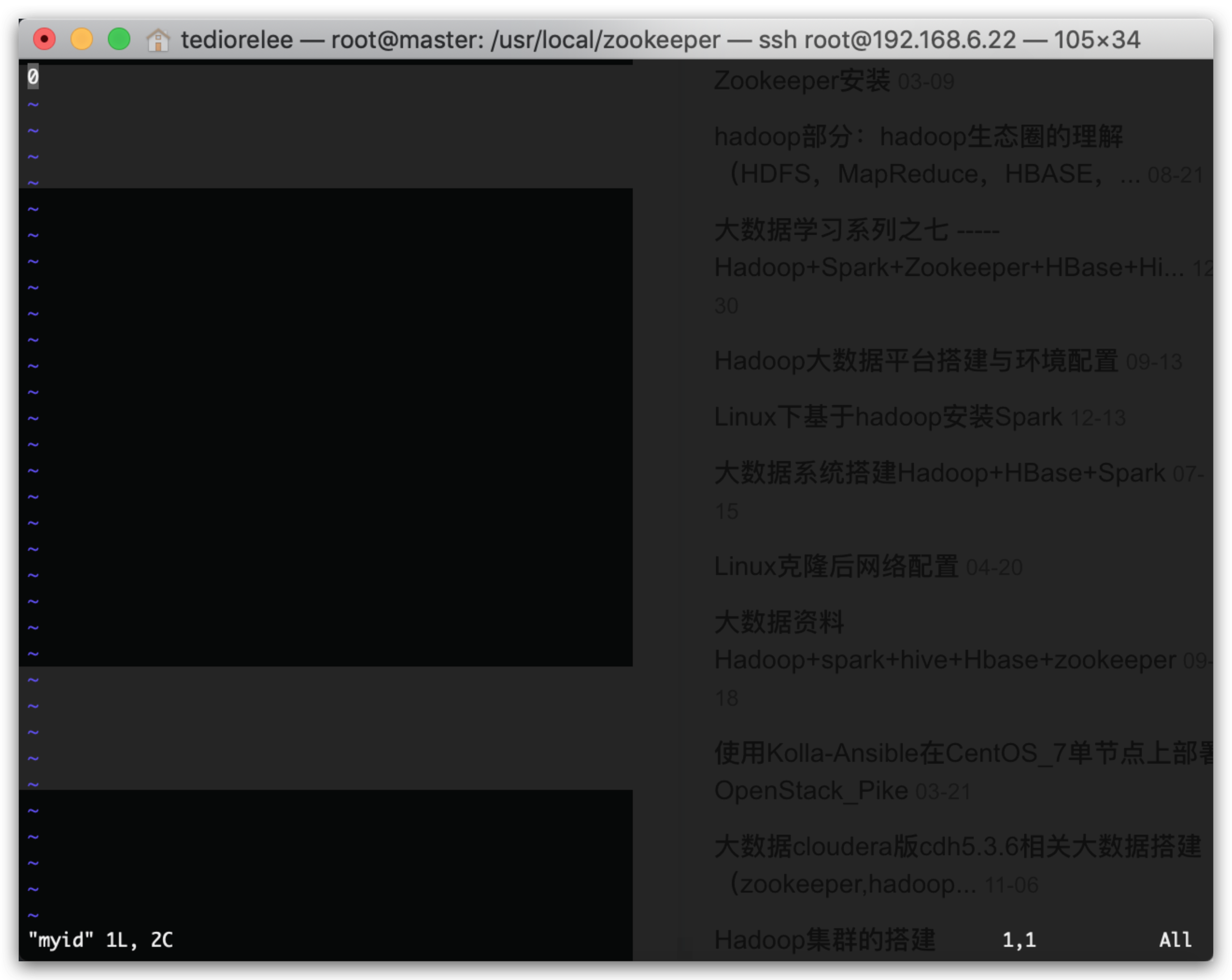
配置myid文件
cd ..
mkdir data
cd data
vim myid
在myid文件中输入0即可
测试
在usr/local/zookeeper/zookeeper-3.4.10目录中
输入bin/zkServer.sh start即可启动zookeeper服务
jps查看,有QuromPeerMain进程表示启动成功。
安装Kafka
介绍
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即主题(Topic),通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息。Consumer,即消费者,消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
安装Scala
Kafka由Java和Scala编写,所以我们先要安装配置Scala
cd /usr/local
mkdir scala
cd scala/
#用winscp把scala安装包上传到该文件夹并解压
tar -zxvf scala-2.11.8.tgz
配置环境变量
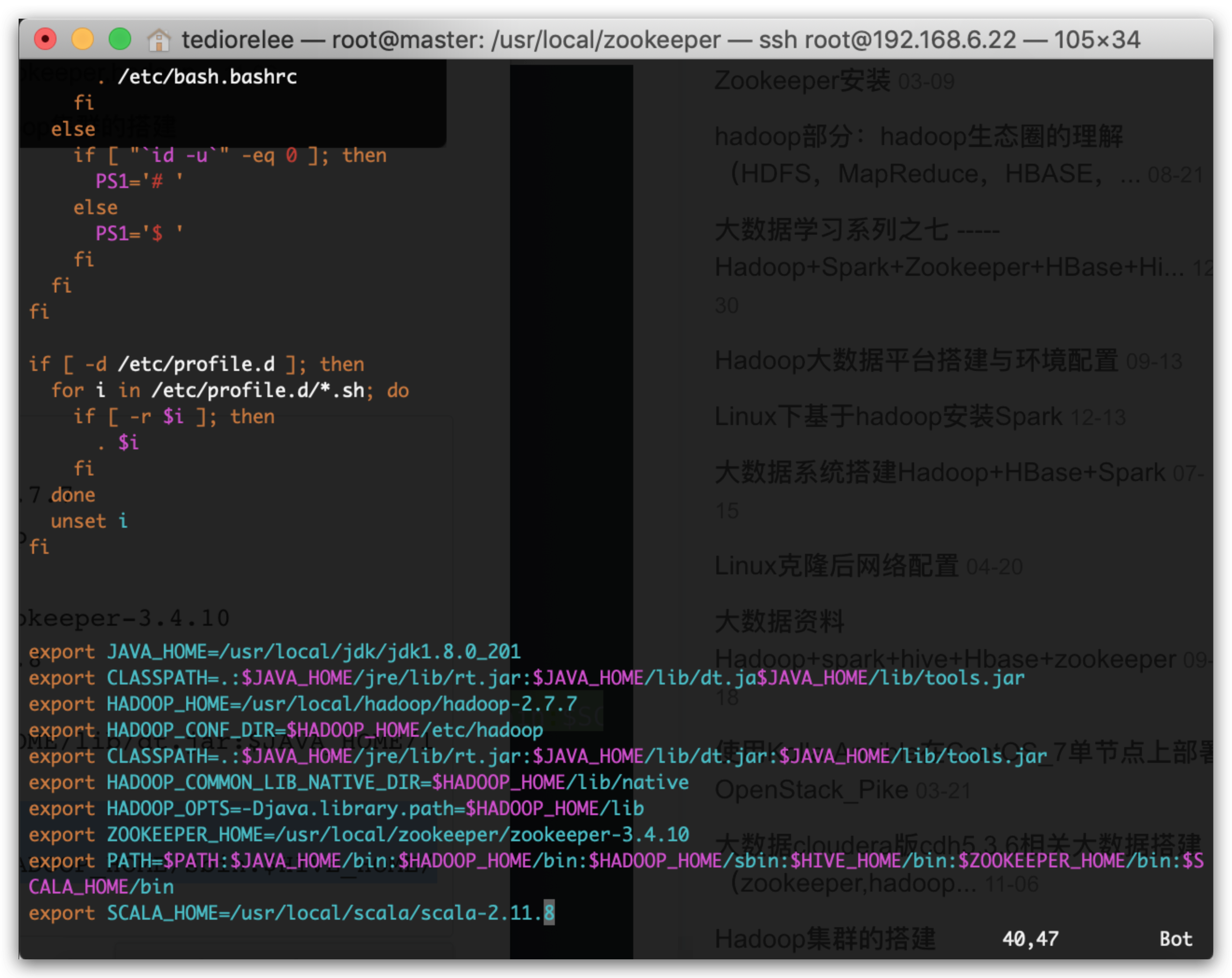
进入vim /etc/profile,对比修改:
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$SCALA_HOME/bin
如图所示:
保存退出并source /etc/profile使其生效
验证是否安装成功,输入scala -version即可查看版本信息

配置Kafka
创建目录,把压缩包用winscp上传
mkdir kafka
cd kafka
tar -zxvf kafka_2.11-2.1.0.tgz
mv kafka_2.11-2.1.0 kafka-2.1.0
修改server.properties文件
vim kafka-2.1.0/config/server.properties
找到如下字段并对应修改
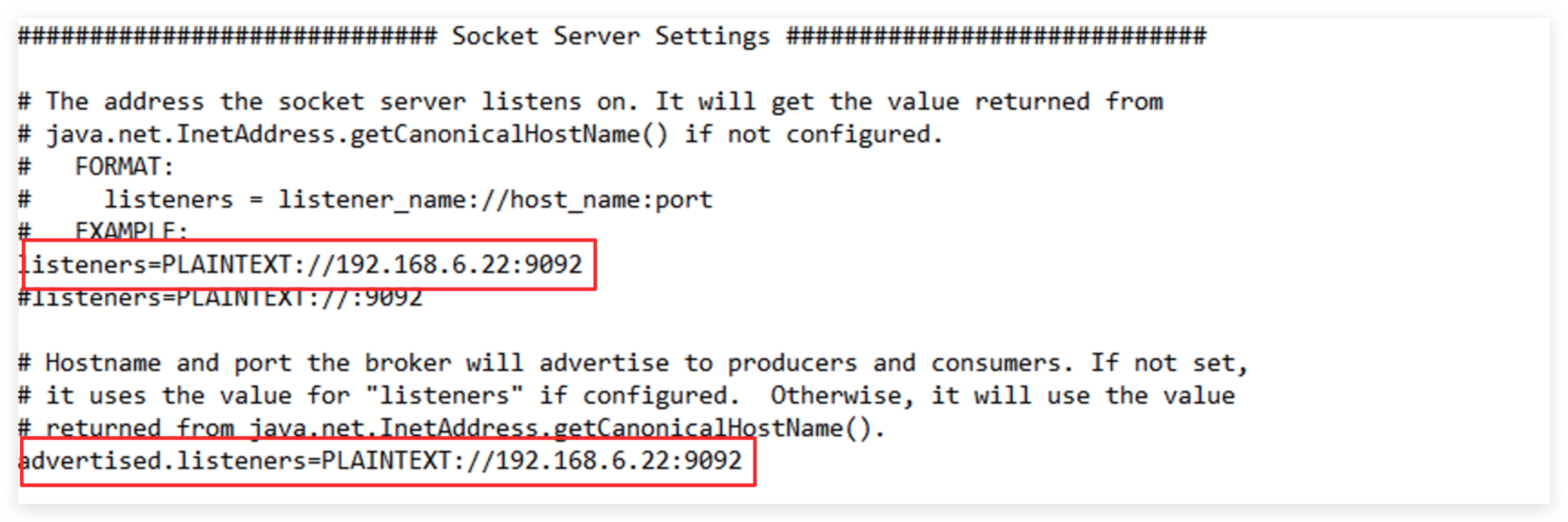
broker.id=0
listeners=PLAINTEXT://192.168.6.22:9092
advertised.listeners=PLAINTEXT://192.168.6.22:9092
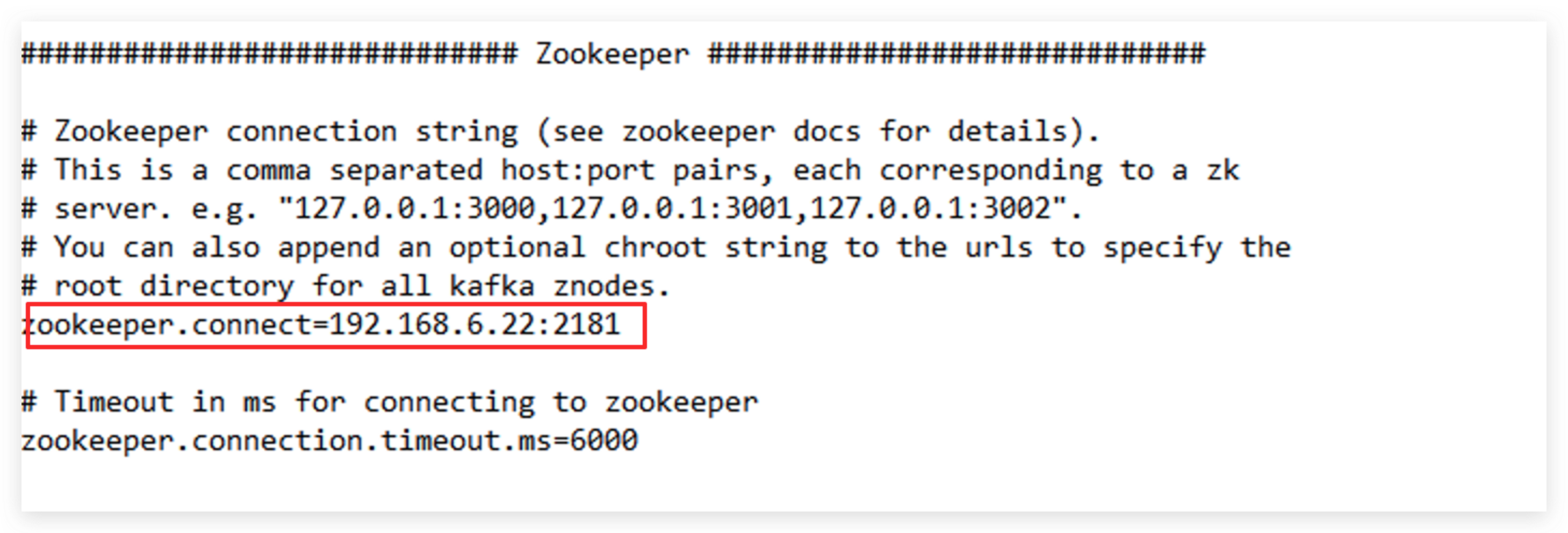
zookeeper.connect=192.168.6.22:2181
如图
测试
启动kafka
cd kafka/kafka-2.1.0/
bin/kafka-server-start.sh config/server.properties &
jps查看进程

安装Flume
介绍
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统),支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中,可以高效率的将多个网站服务器中收集的日志信息存入HDFS/HBase中。
环境配置
创建目录,使用winscp把压缩包上传
mkdir flume
cd flume
tar -zxvf apache-flume-1.8.0-bin.tar.gz
mv apache-flume-1.8.0-bin flume-1.8.0
如图:
打开vim /etc/profile,如下修改
export JAVA_HOME=/usr/local/java/jdk1.8.0_210
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export FLUME_HOME=/usr/local/flume/flume-1.8.0
export FLUME_CONF_DIR=$FLUME_HOME/conf
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$SCALA_HOME/bin:$FLUME_HOME/bin
如图所示:
source /etc/profile使其生效
修改flume-conf.properties
cd flume-1.8.0/conf
cp flume-conf.properties.template flume-conf.properties
vim flume-conf.properties在文件最后加上如下内容:
#agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/local/flume/logs
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/usr/local/flume/logs_tmp_cp
agent1.channels.channel1.dataDirs=/usr/local/flume/logs_tmp
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://master:9000/logs
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
因为上面监听的文件夹是usr/local/flume/logs所以我们要手动创建
cd /usr/local/flume
mkdir logs
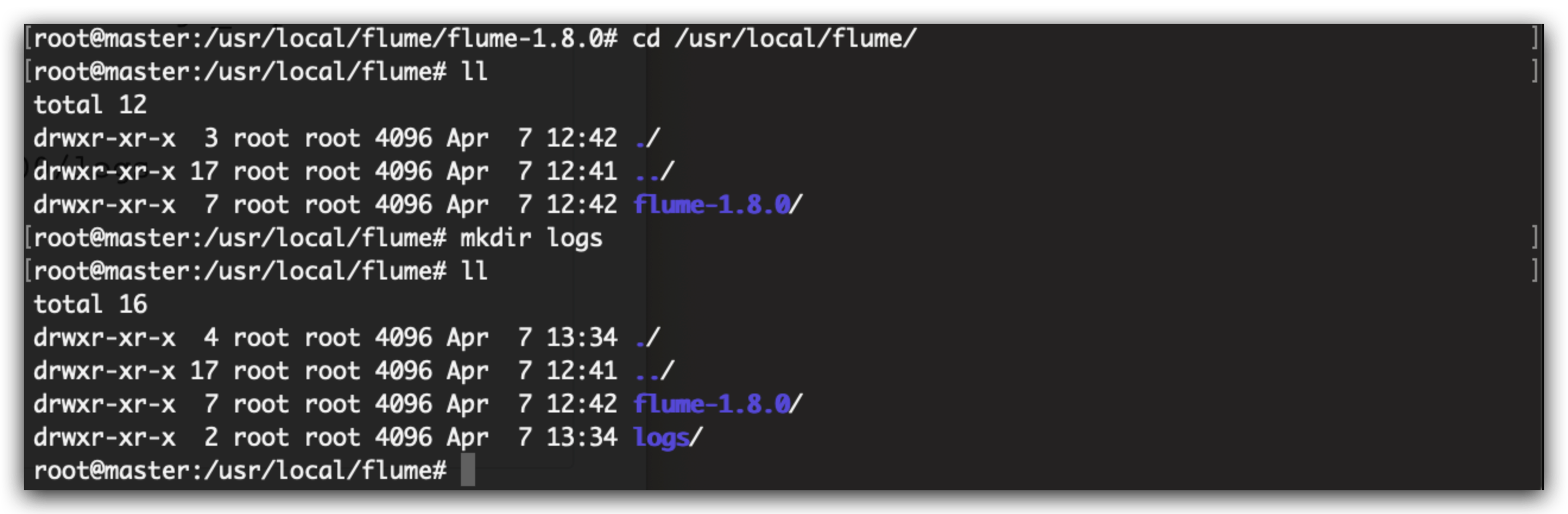
上面的配置文件中 agent1.sinks.sink1.hdfs.path=hdfs://master:9000/logs下,即将监听到的/usr/local/flume/logs下的文件自动上传到hdfs的/logs下,所以我们要手动创建hdfs下的目录
hdfs dfs -mkdir /logs
未完待续….
安装Hbase
介绍
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
环境配置
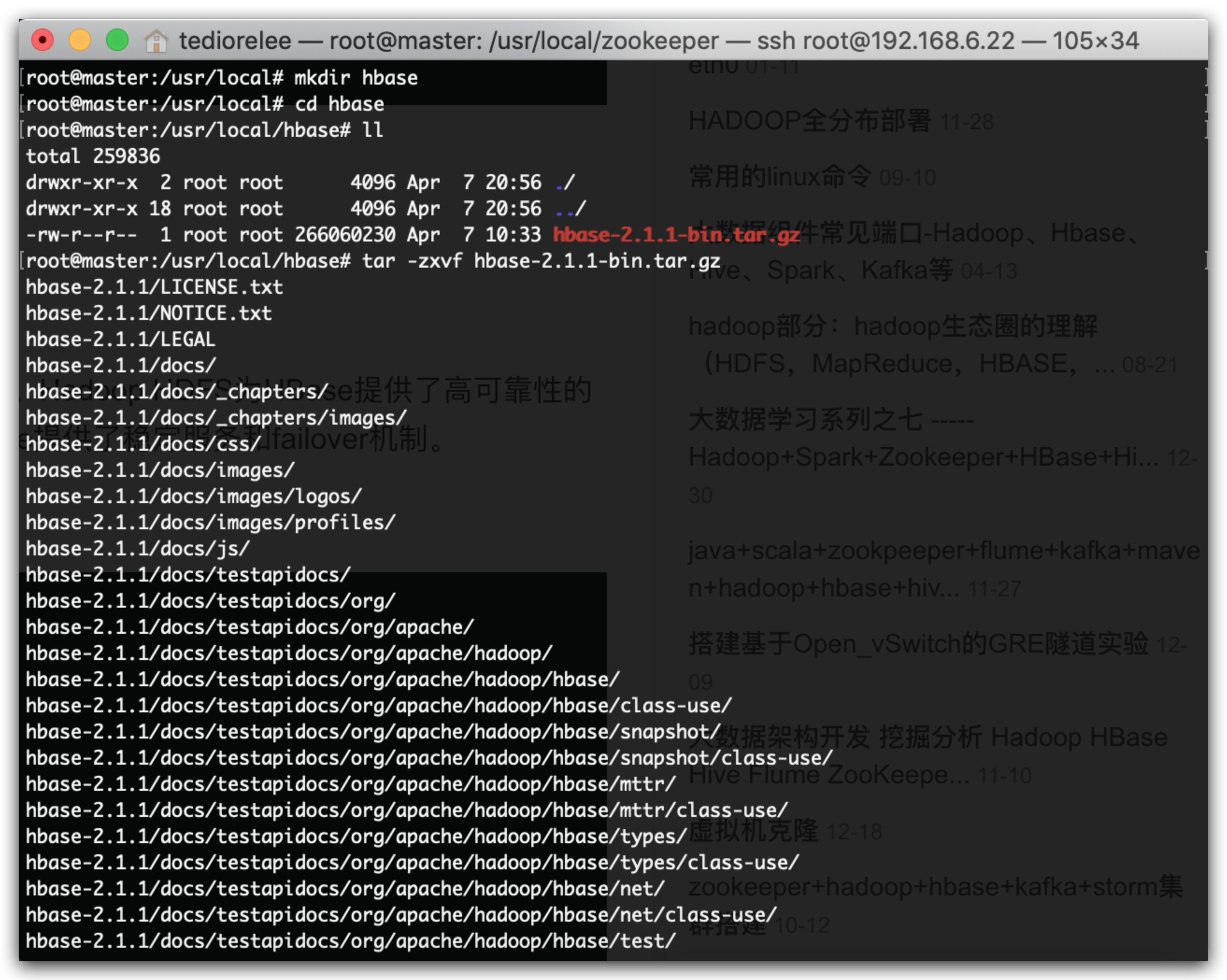
创建目录,使用winscp将压缩包上传
mkdir hbase
cd hbase
tar -zxvf hbase-2.1.1-bin.tar.gz
打开vim /etc/profile环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_210
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export FLUME_HOME=/usr/local/flume/flume-1.8.0
export FLUME_CONF_DIR=$FLUME_HOME/conf
export HBASE_HOME=/usr/local/hbase/hbase-2.1.1
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$SCALA_HOME/bin:$FLUME_HOME/bin:$HBASE_HOME/bin
如图所示
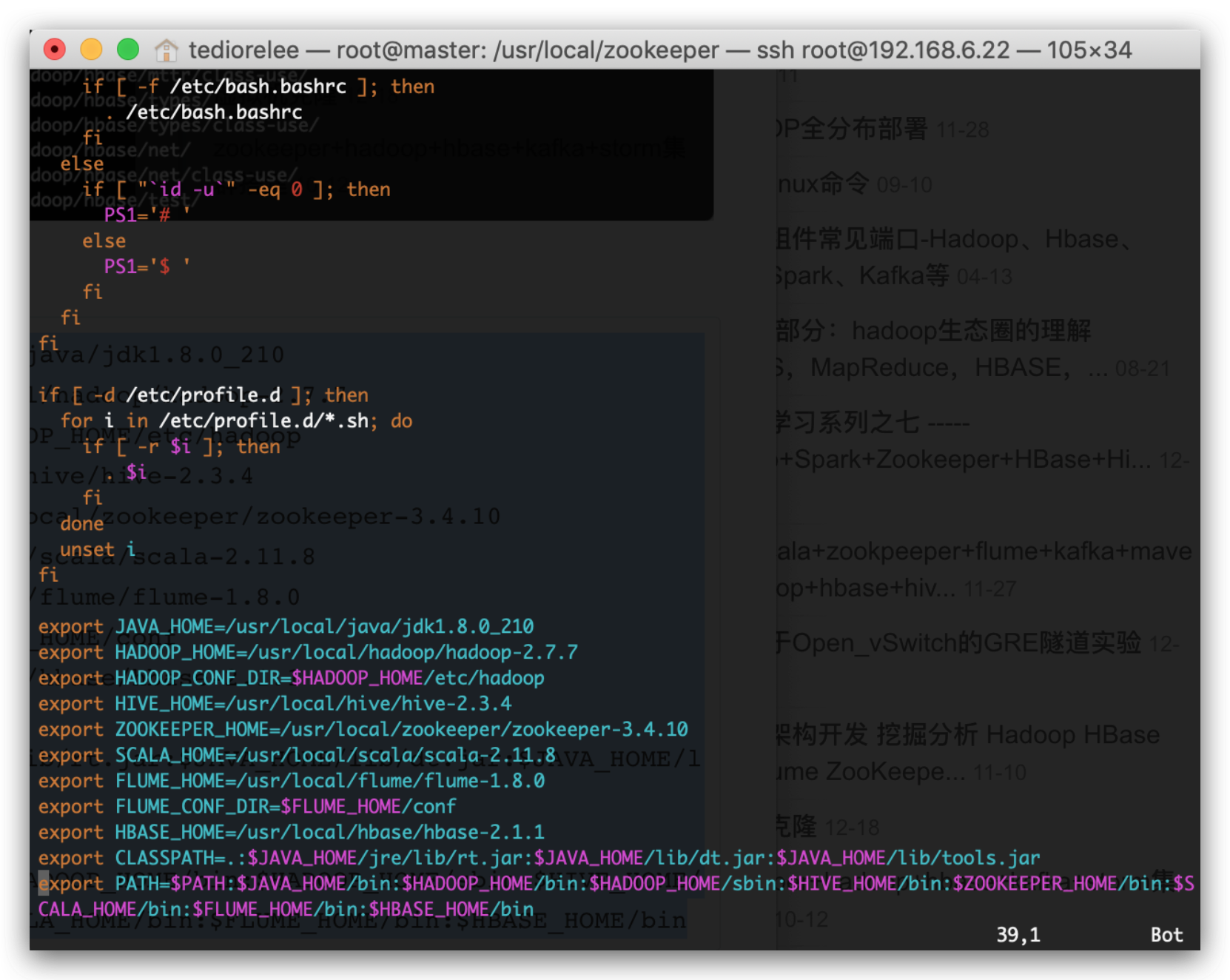
保存退出并source /etc/profile使其生效
配置hbase-env.sh
cd hbase-2.1.1/conf
vim hbase-env.sh
#后面添加如下字段
export JAVA_HOME=/usr/local/java/jdk1.8.0_210
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export HBASE_MANAGES_ZK=false
如图
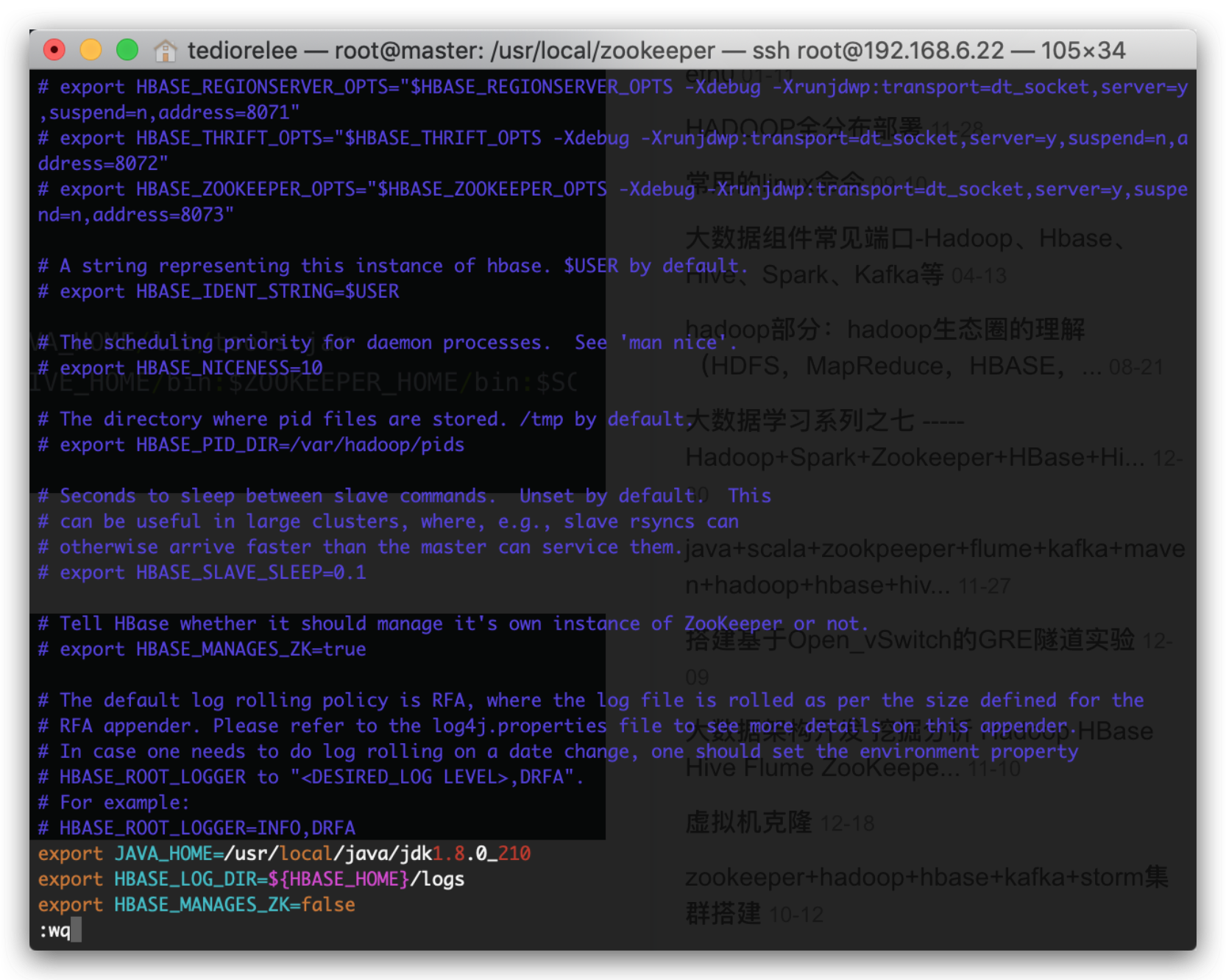
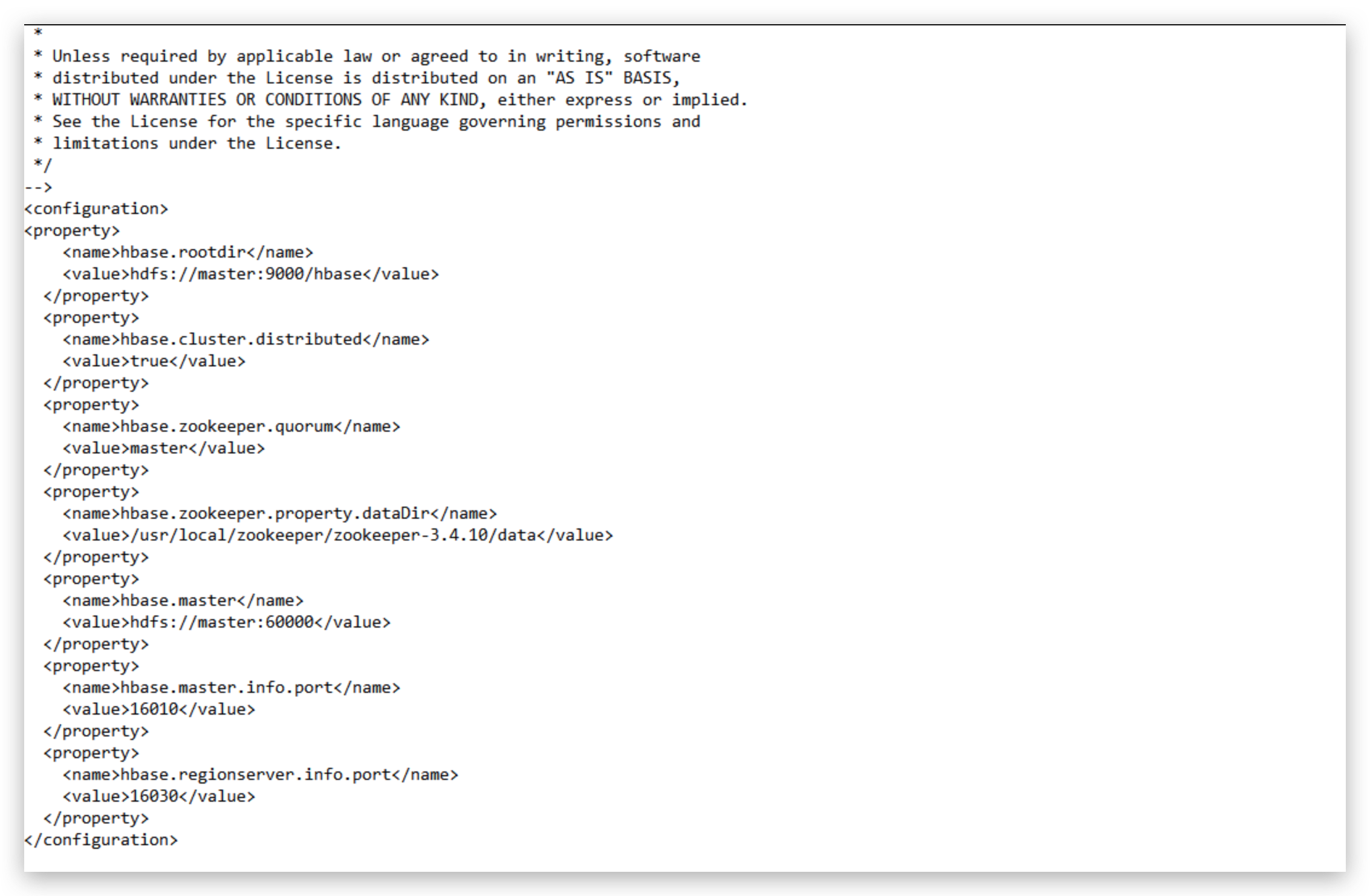
配置hbase-site.xml
编辑vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper/zookeeper-3.4.10/data</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://master:60000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>16030</value>
</property>
</configuration>
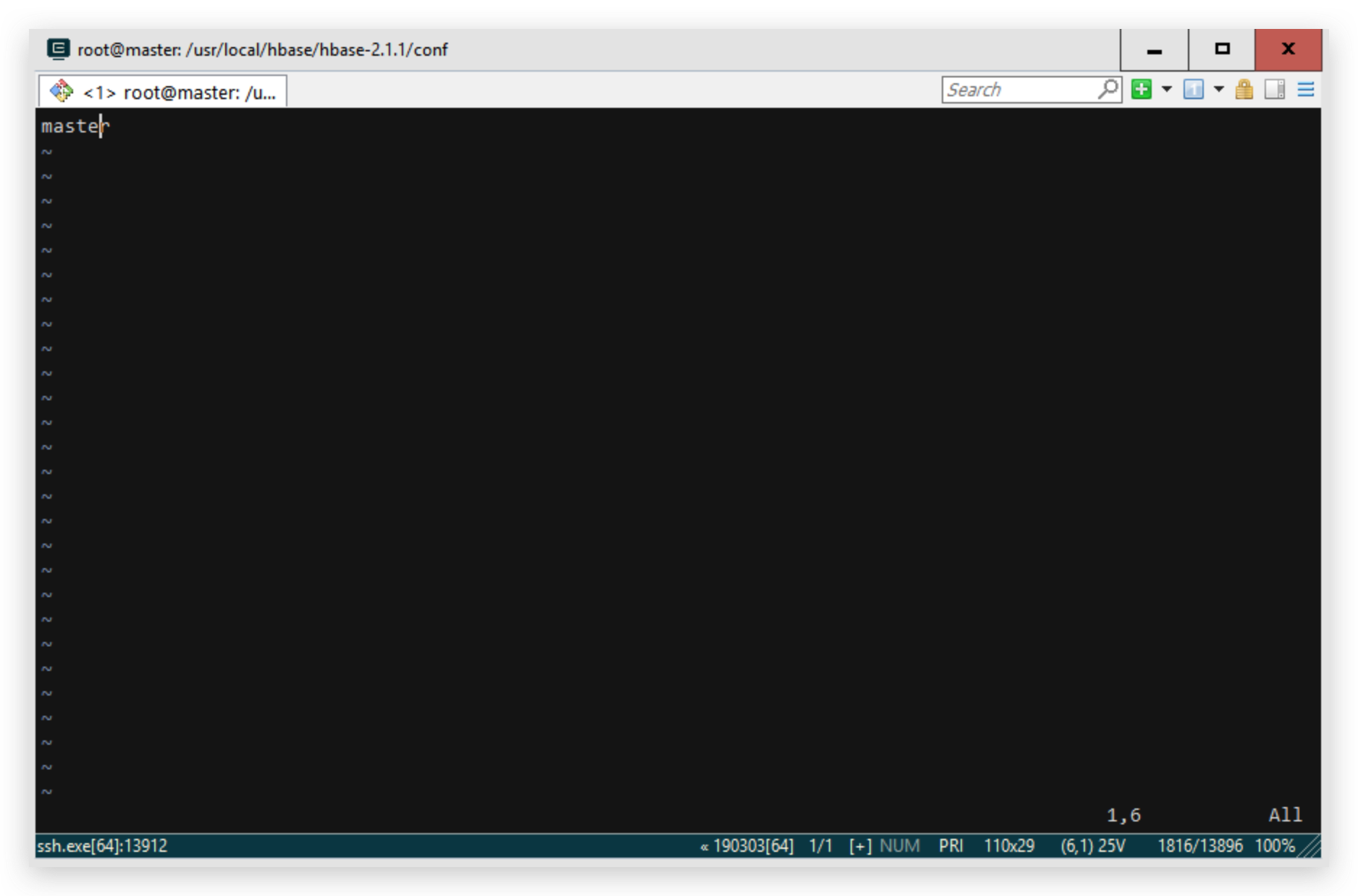
配置regionservers文件
因为我这里只有一个master节点,故文件里只修改master
vim regionservers
master
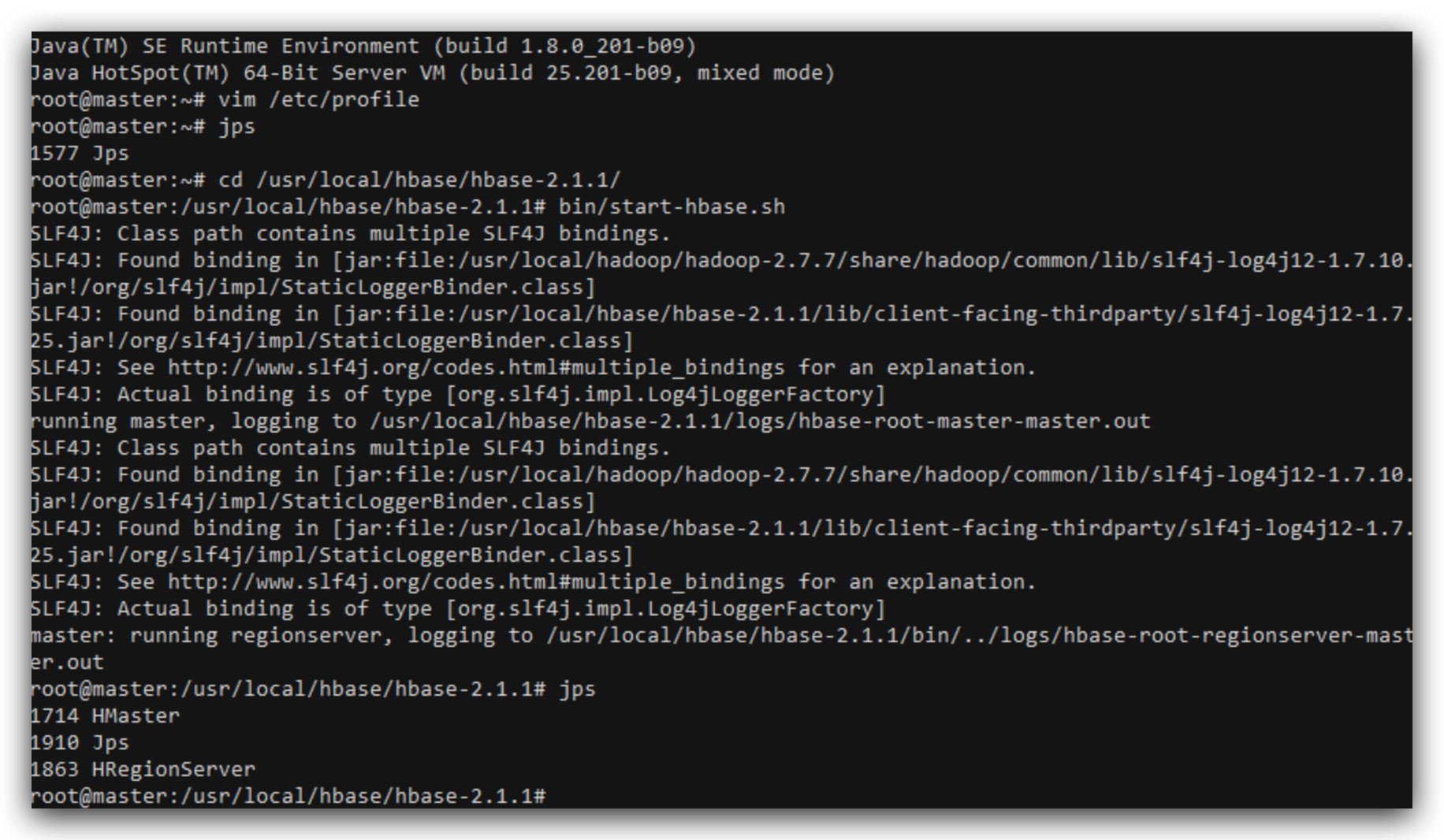
测试
cd hbase/hbase-2.1.1
bin/start-hbase.sh
jps
查看是否启动了HMaster和HRegionServer,如图所示
安装Spark
介绍
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,是类似于Hadoop MapReduce的通用并行框架。Spark拥有Hadoop MapReduce所具有的优点,但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark实际上是对Hadoop的一种补充,可以很好的在Hadoop 文件系统中并行运行。
环境配置
创建目录,使用winscp将压缩包上传
mkdir spark
cd spark
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
mv spark-2.4.0-bin-hadoop2.7 spark-2.4.0
修改系统变量
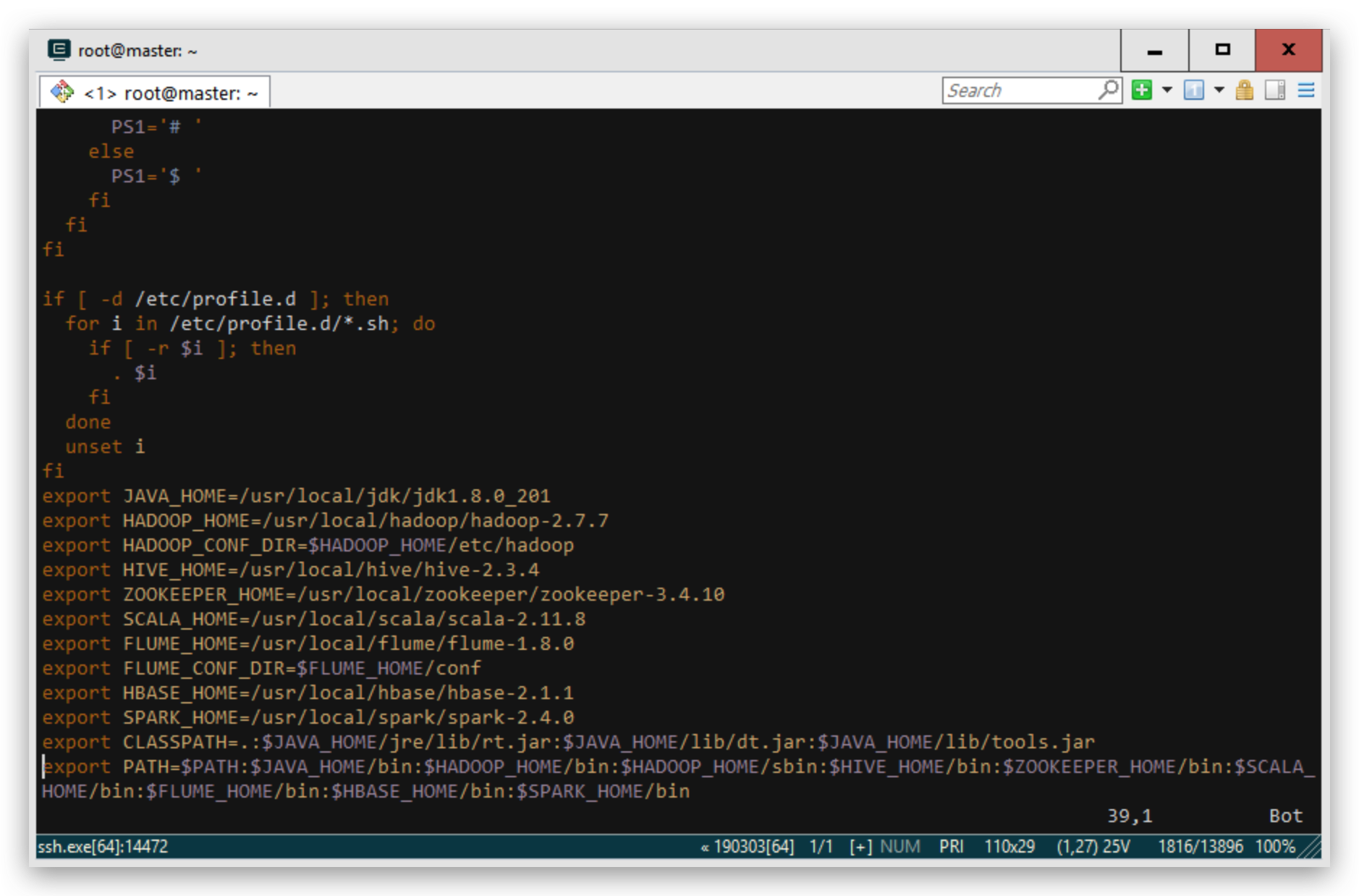
vim /etc/profile
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_201
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export FLUME_HOME=/usr/local/flume/flume-1.8.0
export FLUME_CONF_DIR=$FLUME_HOME/conf
export HBASE_HOME=/usr/local/hbase/hbase-2.1.1
export SPARK_HOME=/usr/local/spark/spark-2.4.0
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$SCALA_HOME/bin:$FLUME_HOME/bin:$HBASE_HOME/bin:$SPARK_HOME/bin
保存退出并source /etc/profile
配置spark-env.sh文件
cd spark-2.4.0/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
#
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_201
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.7.7/etc/hadoop
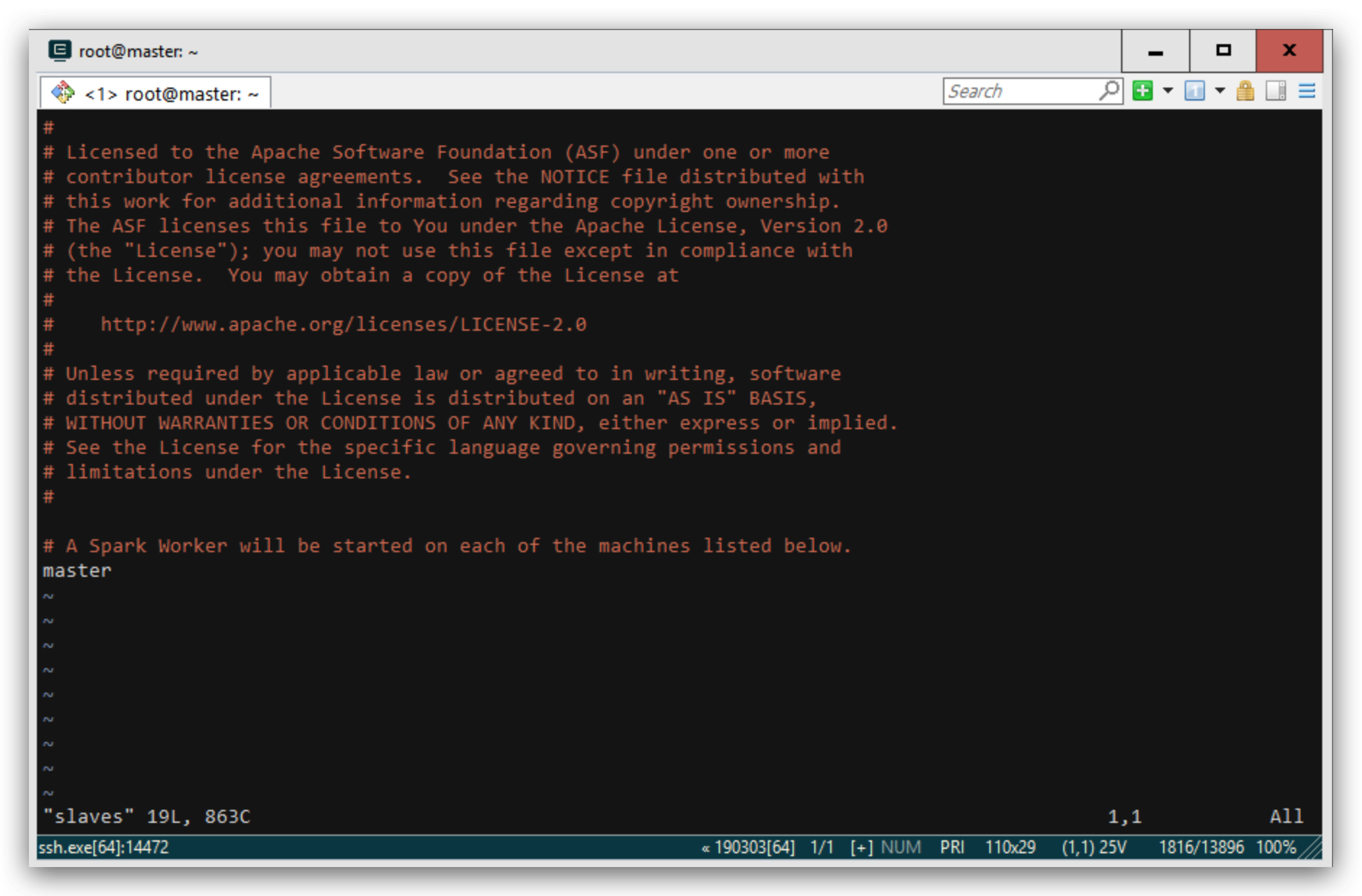
配置slaves文件
mv slaves.template slaves
vim slaves
master
如图所示:
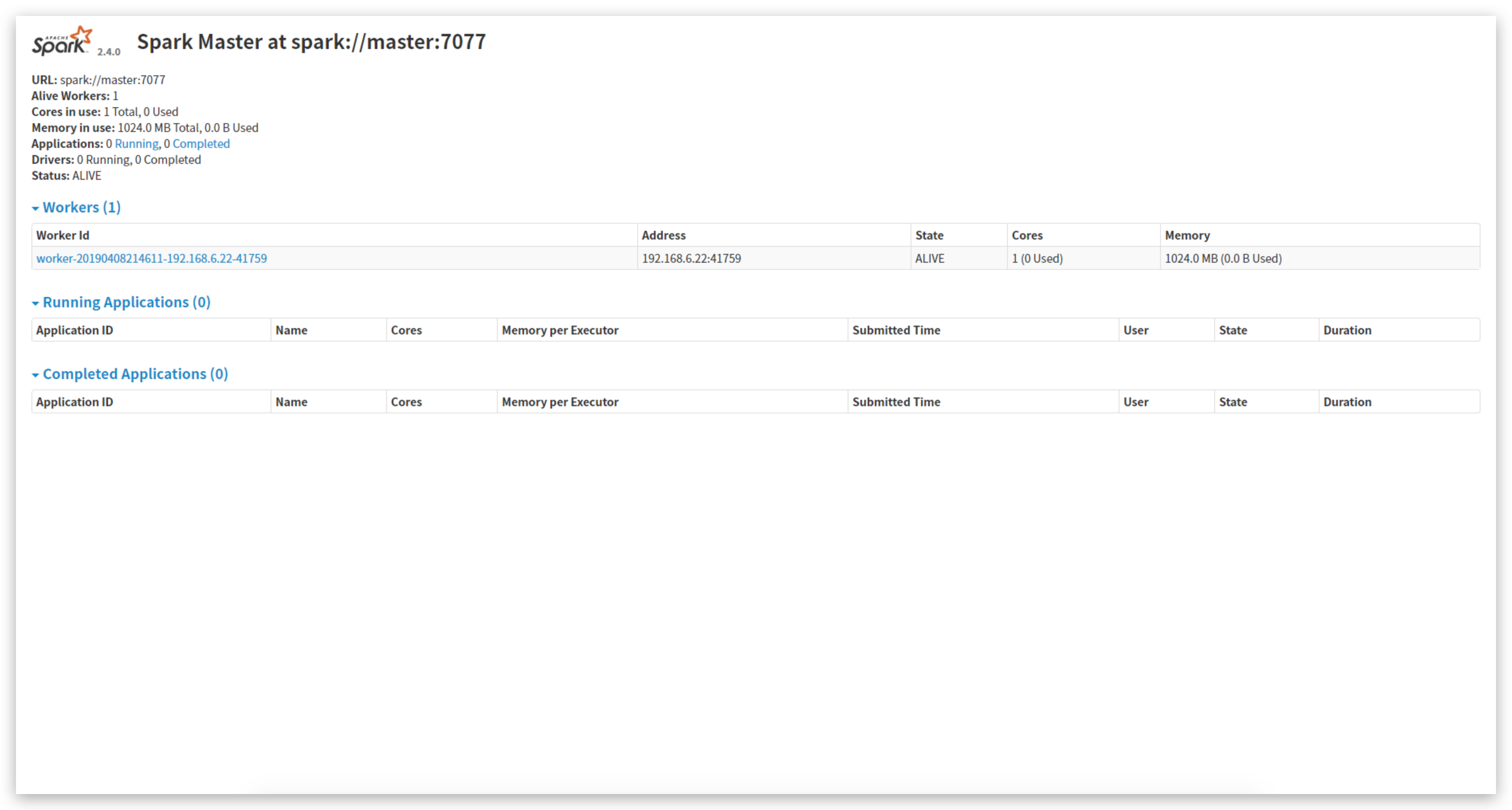
打开浏览器http://192.168.6.22:8080/
测试
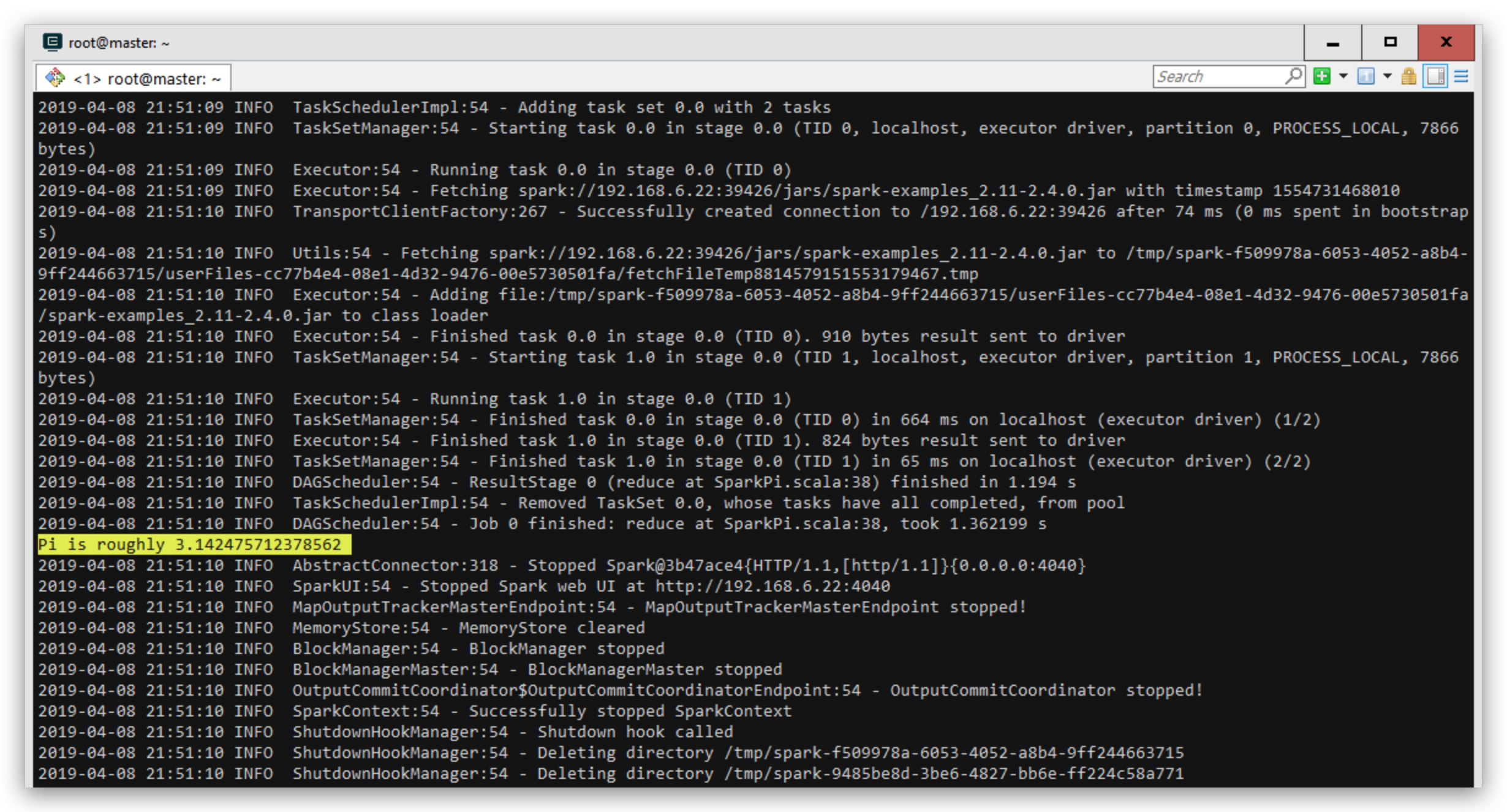
使用Spark自带的计算圆周率做测试
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local \
examples/jars/spark-examples_2.11-2.4.0.jar
在控制台中可以找到输出的结果